
Kontrollierte Ausgaben von Sprachmodellen
Die rasante Entwicklung großer Sprachmodelle (LLMs) hat deren Integration in automatisierte Systeme massiv vorangetrieben. Immer häufiger finden sich LLMs in komplexen Pipelines, in denen sie Textdaten analysieren und verarbeiten. Doch mit ihrer zunehmenden Nutzung wird eine Herausforderung immer deutlicher: Wie stellt man sicher, dass der Output eines Sprachmodells so strukturiert ist, dass andere Systeme ihn zuverlässig verarbeiten können? Zwei Ansätze bieten hier Lösungen: strukturierter Output und strukturierte Generierung. Obwohl die Begriffe oft synonym verwendet werden, unterscheiden sie sich grundlegend und haben jeweils spezifische Vor- und Nachteile.
Strukturierter Output
Strukturierter Output bezeichnet jede Art von Ausgabe, die einer definierten Struktur entspricht. Beispiele hierfür sind JSON, XML oder HTML. Ein Sprachmodell wird dabei so angewiesen, dass sein Output von Beginn an eine vorgegebene Form einhält. Die Struktur der Ausgaben wird dadurch vorhersag- und verarbeitbar.
Feinabgestimmte Modelle
Ein Ansatz, um strukturierten Output zu erhalten, ist das Training eines Modells, das speziell dafür ausgelegt ist, korrekten Output in einer bestimmten Struktur zu erzeugen. OpenAI’s Function Calling API ist ein Paradebeispiel. Diese Modelle erkennen nicht nur, wann externe Funktionen erforderlich sind, um eine Aufgabe zu lösen, sondern generieren auch die notwendigen Parameter direkt im gewünschten Format – etwa in gültigem JSON. Die Funktionalität stützt sich dabei auf genaue Schema-Definitionen, wie sie durch Bibliotheken wie Pydantic vorgegeben werden.
Ein zentraler Vorteil dieser Modelle liegt darin, dass sie explizit darauf trainiert wurden, strukturierten Output basierend auf vordefinierten Schemata zu erzeugen. Diese Spezialisierung steigert ihre Effizienz erheblich und macht sie besonders nützlich für komplexe Aufgaben. Allerdings gibt es keine Garantie, dass die Ausgaben in jedem Fall vollständig mit dem vorgegebenen Schema übereinstimmen. Dies kann insbesondere dann problematisch sein, wenn das Schema oder die Aufgabe sehr komplex ist.
Für ein Gesamtsystem stellt es eine erhebliche Herausforderung dar, wenn das Sprachmodell zwar in 99 % der Fälle korrekte Ergebnisse liefert, aber gelegentlich fehlschlägt. Selbst seltene Fehler können zu schwerwiegenden Problemen führen, da nachgelagerte Systeme oft keine Möglichkeit haben, solche Abweichungen zu korrigieren. Eine hundertprozentige Zuverlässigkeit bleibt daher ein schwer erreichbarer Zielpunkt in der Entwicklung solcher Lösungen.
Vorteile:
Speziell trainierte Modelle erzeugen zuverlässig strukturierten Output.
Effizient bei komplexen Aufgaben dank Anpassung an definierte Schemata.
Nachteile:
Keine Garantie, dass Ausgaben immer dem Schema entsprechen, besonders bei hoher Komplexität.
Seltene Fehler können nachgelagerte Systeme erheblich stören.
Strukturierte Generierung
Strukturierte Generierung hingegen greift direkt in den Textgenerierungsprozess ein. Der Sampling-Prozess von Sprachmodellen ist autoregressiv: Token werden Schritt für Schritt generiert, basierend auf dem Kontext der vorherigen Token. Bei der strukturierten Generierung wird dieser Prozess modifiziert, indem der Suchraum des Modells eingeschränkt wird.
Ein Beispiel ist die Verwendung von regulären Ausdrücken (RegEx) oder kontextfreien Grammatiken, die genau definieren, welche Token in Frage kommen. Dies wird etwa von der Open-Source-Bibliothek Outlines ermöglicht. Sie setzt auf sogenannte Finite-State-Machines (FSM), die den generierten Text gegen definierte Muster prüfen. Durch die Implementierung solcher Methoden kann sichergestellt werden, dass der Output direkt einem gewünschten Schema entspricht, ohne dass das Modell speziell dafür trainiert werden muss. Wenn ein Modell etwa Python-Code generieren soll, kann die FSM sicherstellen, dass nach dem Schlüsselwort def nur gültige Python-Syntax folgt, z. B. ein Funktionsname.
Das Verfahren ist effizient, da die FSM und die zugehörige Maskierung außerhalb des Generierungsprozesses erstellt werden. Dennoch gibt es Herausforderungen: Der Speicherbedarf für komplexe FSMs kann in die Höhe schnellen, insbesondere bei sehr großen Vokabularen oder umfangreichen regulären Ausdrücken.
Strukturierte Generierung kann auch verwendet werden, um unstrukturierten Output zu erzeugen. Nehmen wir die Frage: „What are better pets, cats or dogs?“ Hierbei könnte man sicherstellen, dass der Output eine klare Aussage in einer bestimmten Form ist, zum Beispiel: „Cats are better pets“ oder „Dogs are better pets“.
question: "What are better pets, cats or dogs?"
pet_schema = r'"([Cc]ats|[Dd]ogs) are better pets"'
# Nutze strukturierte Generierung mit dem definierten Schema
structured_output = outlines.generate.regex(
model,
pet_schema,
sampler="greedy"
)Vorteile:
Flexibel einsetzbar, da keine Anpassung des Modells notwendig ist.
Garantiert, dass der Output dem gewünschten Format entspricht.
Nachteile:
Erhöhter Rechenaufwand.
Für komplexe Schemata steigt der Speicherbedarf.
Kombination aus strukturiertem Output und strukturierter Generierung
Strukturierte Generierung und strukturierter Output können gemeinsam verwendet werden, um maximale Präzision und Zuverlässigkeit zu erreichen. Strukturierte Generierung hat keine semantische Intelligenz. Wenn ein Sprachmodell generell nicht in der Lage ist, die gewünschte Aufgabe zu lösen, wird strukturierte Generierung auch keine brauchbaren Ergebnisse liefern. Sie kann lediglich garantieren, dass der Output einer formalen Vorgabe entspricht. Ein speziell abgestimmtes Modell den semantischen Kontext besser verstehen und die Wahrscheinlichkeit erhöhen, dass die generierten Inhalte korrekt sind.

Eine NLP Kontroverse: „Let Me Speak Freely“ vs. Outlines
Im Sommer 2024 entfachte ein Paper mit dem Titel „Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models“ in der NLP-Community eine Diskussion. Das Paper hatte zwei Hauptthesen:
Formatbeschränkungen reduzieren die Leistungsfähigkeit von LLMs. Besonders Aufgaben, die logisches Denken oder komplexe Verarbeitung erfordern, würden durch strukturierte Generierung schlechter gelöst.
Je strenger die Formatvorgaben, desto größer die Leistungseinbußen.
Diese Aussagen basierten auf mehreren Tests, bei denen Sprachmodelle mit unterschiedlichen Formatbeschränkungen wie JSON oder Natural Language (NL) verglichen wurden. Dabei wurde berichtet, dass insbesondere JSON-Outputs deutlich schlechter abschnitten – mit teils drastischen Unterschieden.
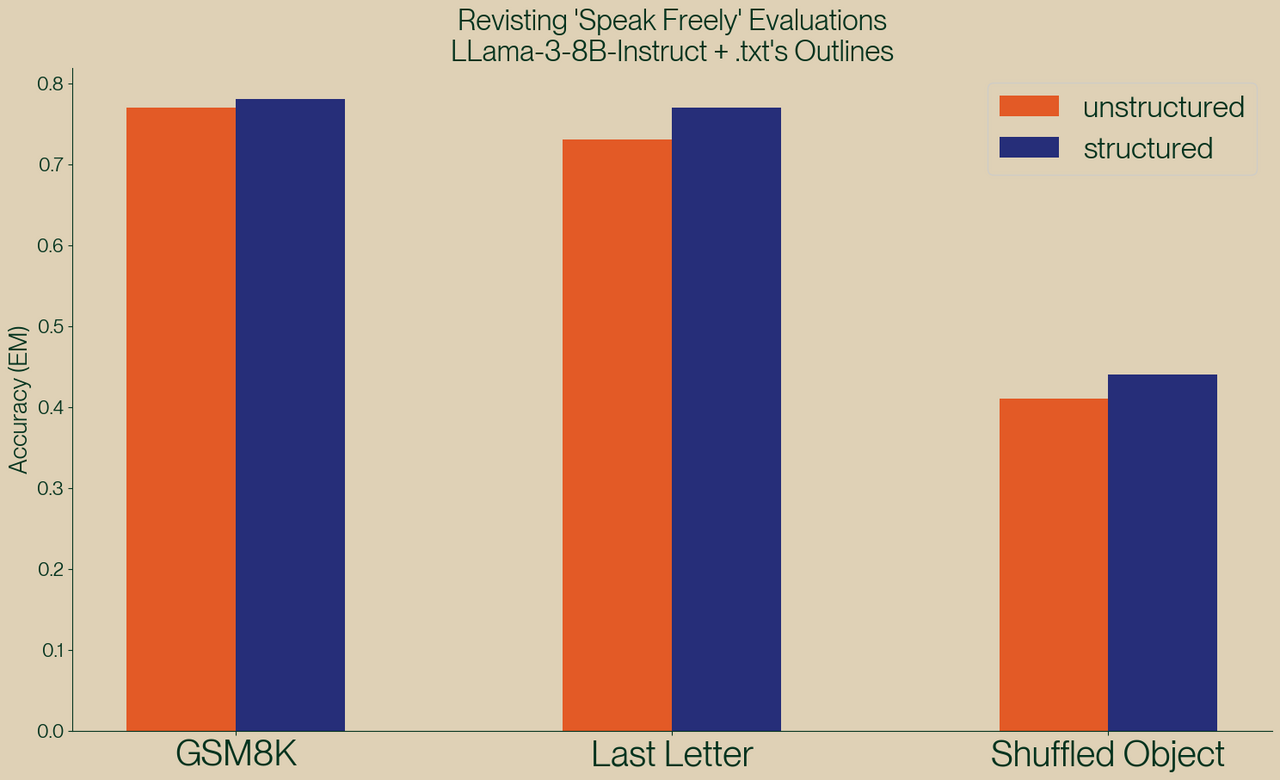
Dies wurde von den Machern der Bibliothek Outlines in einem detaillierten Blogartikel „Say What You Mean: A Response to 'Let Me Speak Freely'“ angezweifelt. Sie wiesen auf methodische Mängel hin, die Zweifel an der Validität der Ergebnisse aufwerfen:
Mangelhafte Prompts: Die für die strukturierte Generierung genutzten Prompts enthielten kaum Hinweise auf das gewünschte Format oder die Struktur. Ein Beispiel: Der Prompt lautete lediglich „You must use the tool“ und ließ völlig offen, dass und wie die Ausgabe in JSON erfolgen sollte. Ohne eine klare Anleitung ist es nicht verwunderlich, dass die Ergebnisse schlecht ausfielen.
Keine einheitlichen Vergleichsbedingungen: Die Prompts für unstrukturierte und strukturierte Generierung unterschieden sich stark. Während unstrukturierte Prompts oft klar und detailliert waren, fehlte es den strukturierten an notwendigen Kontexten. Dies macht die Ergebnisse methodisch schwer vergleichbar.
Unklare Parsing-Methoden: Das Paper verwendete einen sogenannten „AI Parser“, ein zweites Sprachmodell, das die generierten Antworten interpretierte. Outlines argumentiert, dass dieser Parser nicht nur fehleranfällig, sondern auch ein methodisch fragwürdiger Vergleichsmaßstab sei.
Die Macher von Outlines verbesserten die Prompts, indem sie klare Schema-Definitionen und Beispiele hinzufügten, und führten die Experimente erneut durch. Sie erzielten bessere Ergebnisse für die strukturierte Generierung als für unstrukturierte Outputs. Ein Beispiel: Bei der „Last Letter“-Aufgabe stieg die Erfolgsquote für JSON-Outputs von unter 10% auf über 70 %.
Allerdings ist auch das Vorgehen der Macher von Outlines in ihrem Artikel nicht frei von methodischen Schwächen, die die Aussagekraft ihrer Schlussfolgerungen beeinträchtigen können.
Ein zentraler Punkt der Outlines-Argumentation ist die Bedeutung von klaren und beispielhaften Prompts. In ihren Prompts präsentieren sie dem Sprachmodell nicht nur die Aufgabenstellung, sondern auch konkrete Beispiele für Eingabe und erwartete Ausgabe. Diese Methode, bekannt als Few-Shot Prompting oder In-Context Learning, ist in der NLP-Literatur eine etablierte Technik, die vielfach gezeigt hat, dass sie die Ergebnisse von Sprachmodellen signifikant verbessern kann.
Diese Ansätze halfen dem Modell in den Outlines-Experimenten, den gewünschten Output besser zu verstehen und präziser umzusetzen. Jedoch wirft dies eine wichtige methodische Frage auf: Beruht die verbesserte Leistung wirklich auf der strukturierten Generierung oder lediglich auf den besseren Prompts?
Die Outlines-Autoren argumentieren, dass strukturierte Generierung entscheidend sei, um Fehler zu minimieren und den Output konsistent zu machen. Gleichzeitig ist es jedoch naheliegend, dass ein Großteil der beobachteten Verbesserung auf das Few-Shot Prompting zurückzuführen ist – eine Technik, die im ursprünglichen Paper „Let Me Speak Freely“ nicht angewendet wurde.
Fazit: Zwei Perspektiven – eine Lektion
Die Kontroverse zwischen dem Paper und dem Blogartikel zeigt vor allem eines: Die Qualität der Ergebnisse hängt entscheidend von der Methodik ab. Strukturierte Generierung ist kein Allheilmittel und kann nicht die grundsätzlichen Fähigkeiten eines Sprachmodells erweitern. Sie kann jedoch, richtig angewandt, entscheidend dazu beitragen, Outputs vorhersehbarer und zuverlässiger zu machen.
Wichtig bleibt dabei:
Prompts sind entscheidend: Ein schlecht formulierter Prompt führt unweigerlich zu schlechten Ergebnissen – unabhängig davon, ob strukturierte Generierung genutzt wird.
Vergleichbarkeit ist zentral: Um faire Aussagen treffen zu können, müssen alle Bedingungen – von Prompts bis Parsing-Methoden – einheitlich sein.
Strukturierte Generierung hat Potenzial: Besonders in Kombination mit Techniken wie Few-Shot Prompting und klar definierten Schemas kann sie die Leistung von Sprachmodellen erheblich verbessern.
Die rasante Entwicklung von Sprachmodellen bringt viele neue Möglichkeiten mit sich, doch sie geht auch mit Herausforderungen einher. Forschung und Veröffentlichungen in diesem Bereich stehen unter starkem Druck, Aufmerksamkeit zu gewinnen – oft durch überraschende oder kontroverse Ergebnisse. Dies kann dazu führen, dass methodische Schwächen übersehen oder bestimmte Ergebnisse überbetont werden.
Für Anwender und Forscher ist es daher entscheidend, solche Behauptungen kritisch zu hinterfragen und die zugrunde liegenden Prozesse genau zu verstehen. Ein tiefes technisches Verständnis sowie die Fähigkeit, Experimente sorgfältig zu reproduzieren, sind unerlässlich, um valide Schlussfolgerungen zu ziehen und die tatsächlichen Möglichkeiten und Grenzen von Sprachmodellen zu erkennen.
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Headergrafik erstellt mittels DALL-E im Dezember 2024
Datum: 12.12.2024
Autor

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.