
Das Problem von Halluzinationen der Large Language Models (LLMs) – also das Erzeugen von falschen oder irreführenden Informationen - kann durch Retrieval Augmented Generation (RAG) minimiert werden. Hierbei wird der Output von Large Language Models (LLMs) durch spezifische Kontextdokumente beeinflusst. Das Modell kann so auf Wissen zurückgreifen, welches im Trainingsdatenset nicht vorhanden war (z.B. aktuelle Nachrichten oder unternehmensinterne Daten).
LLMs haben kein Langzeitgedächtnis, sondern ein begrenztes Kontextfenster. ChatGPT kann sich z.B. nur an die Informationen der aktuellen Konversation erinnern und auch nur so lange, wie diese nicht zu lang wird.
Es werden ständig Methoden erforscht, diese offensichtliche Schwachstelle von LLMs zu beseitigen und die Größe des Kontextfensters zu erweitern. Technologien wie Flash Attention, Ring Attention und Infini Attention sind Beispiele hierfür und aktuelle Modelle übertreffen sich regelmäßig in der Größe ihres Kontextfensters (Anthropics Claude und Gemini 1.5 Pro werben inzwischen mit bis zu 1 Millionen Tokens). Es stellt sich die Frage, ob RAG-Methoden durch solch ausgedehnte Kontextfenster obsolet werden könnten. Während es verlockend erscheint, eine gesamte Datenbank in das Kontextfenster eines LLMs zu integrieren, zeigen aktuelle Forschungsergebnisse, dass der Zugriff auf diese Informationen weiterhin komplexe Herausforderungen darstellen.
"Needle in a Haystack"-Test
Ein wiederkehrendes Thema in unserer Diskussion war der sogenannte "Needle in a Haystack"-Test, der die Fähigkeit eines LLM untersucht, spezifische Informationen aus einem langen Kontextfenster mit sonst irrelevanten Informationen zu extrahieren (z.B. das Wiedergeben eines spezifischen Hash-Wertes aus einer sehr langen Tabelle).
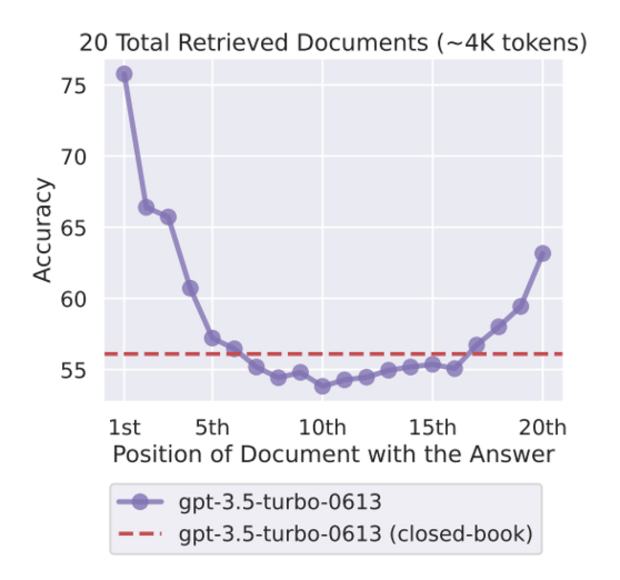
Der "Lost-in-the-Middle"-Effekt
Ein besonders interessantes Phänomen, ist der sogenannte "Lost-in-the-Middle"-Effekt (benannt nach der gleichnamigen Forschungsarbeit), der zeigt, dass LLMs dazu neigen, Informationen am Anfang oder Ende ihres Kontextfensters zuverlässiger wiederzugeben als solche, die sich in der Mitte befinden.
Diese Beobachtung deutet darauf hin, dass LLMs während des Trainings eine gewisse Voreingenommenheit entwickeln. Der Beginn eines Textes enthält oft wichtige einführende Informationen (und den System-Prompt beim Imstruction Tuning) und das Ende des Kontextfensters ist besonders relevant für den unmittelbar folgenden Text. Diese Abschnitte werden daher von den Modellen stärker gewichtet.
Das Modell lernt eine für die Trainingsdaten hilfreiche Daumenregel, ignoriert dadurch aber potentiell wichtige Informationen, wenn sie ungünstig positioniert sind.
Beim Entwerfen von RAG-Systemen sind diese Effekte bei der Art, wie wir dem Modell die Kontext-Dokumente präsentieren, ebenfalls zu beachten.

Balanceakt zwischen Kontexttreue und Vorwissen
Forschungsarbeiten wie "How faithful are RAG models?" und "LLM In-Context Recall is Prompt Dependent", beleuchten die interne Spannung in Large Language Models (LLMs) zwischen den im Kontextfenster vorhandenen Informationen und dem apriorischen Wissen, das die Modelle während des Trainings erwerben.
Diese Studien zeigen, dass LLMs oft Schwierigkeiten haben, sich in ihren Antworten strikt an die ihnen bereitgestellten Dokumente zu halten, besonders dann, wenn die Kontextinformationen stark von ihrem während des Trainings erlernten Wissen abweichen.
Ein Test zeigt, dass GPT-4, obwohl es nicht genau die empfohlene Dosis eines Medikaments kennt, eine Antwort liefert, die sehr nahe an der richtigen liegt. Wenn das korrekte Kontextdokument bereitgestellt wird, reproduziert GPT-4 die richtige Antwort. Wird die Dosis im Dokument jedoch so verändert, dass sie erheblich von GPT-4s erlerntem Wissen abweicht, greift das Modell stattdessen auf sein Vorwissen zurück. Dies zeigt, dass GPT-4 intern abwägt, welche Informationen aus dem Kontextfenster als glaubwürdig angesehen werden. Obwohl dies in manchen Fällen vorteilhaft sein kann, verdeutlicht es, dass der Kontext allein kein absolut zuverlässiges Mittel ist, um das Verhalten von LLMs präzise zu steuern.
Ein bemerkenswerter Aspekt, der in der Forschungsarbeit "The Power of Noise" beleuchtet wird, ist die Entdeckung, dass unter bestimmten Umständen das Hinzufügen von irrelevanten Dokumenten zum Kontextfenster eines Large Language Models (LLMs) paradoxerweise die Fähigkeit des Modells verbessern kann, relevante Informationen wiederzugeben.
Fazit
Moderne Large Language Models (LLMs) liefern beeindruckende Ergebnisse, insbesondere bei Aufgaben, für die sie während ihres Trainings Beispiele gesehen haben (was nicht selten der Fall ist, da sie auf gigantischen Textmengen trainiert wurden). Sie demonstrieren auch die Fähigkeit, zusätzliches Wissen aus ihrem Kontext zu integrieren. Allerdings zeigt sich, dass es für LLMs herausfordernder wird, präzise zu antworten, je stärker eine Aufgabe von ihrem trainierten Vorwissen abweicht.
Die diskutierten Beispiele unterstreichen die Grenzen von LLMs im Umgang mit neuen Informationen. Diese Erkenntnisse sind entscheidend, um zukünftig effektivere Retrieval Augmented Generation-Systeme und personalisierte Chat-Assistenten zu entwickeln.
Veröffentlicht am 30.04.2024
Kontaktieren Sie uns
Einstiegsangebot für Unternehmen
Entdecken Sie die Möglichkeiten der künstlichen Intelligenz für Ihr Unternehmen. Kontaktieren Sie uns für eine kostenlose Beratung und entdecken Sie die Vorteile von Sprachmodellen, Machine Learning und Suchtechnologien.
Autor
