
Ob Grok-3 Think, DeepSeek R1 oder OpenAI o3 – die neuesten Entwicklungen in der KI-Welt zeigen, dass Reasoning-Modelle zunehmend in den Fokus rücken. Wir werfen einen genaueren Blick auf ihre Funktionsweisen, ihre Stärken und Schwächen sowie darauf, wie sie trainiert werden.
Bedeutung von Reasoning-Modellen?
Moderne Sprachmodelle (LLMs) wie GPT-4o, Claude 3.5 oder Gemini 2.0 haben beeindruckende Fähigkeiten und können Texte generieren, die oft kaum von menschlichen zu unterscheiden sind. Auch wenn sie in begrenztem Maße abstrahieren können – gewissermaßen zwischen Texten interpolieren – basiert ihre starke Leistung dennoch zu einem großen Teil auf dem Auswendiglernen riesiger Trainingsdaten. Bei ungewöhnlichen Problemen, die in ihren Trainingsdaten selten vorkamen, stoßen sie an ihre Grenzen.
Ob Grok-3 Think, DeepSeek R1 oder OpenAI o3 – die neuesten Entwicklungen in der KI-Welt zeigen, dass Reasoning-Modelle zunehmend in den Fokus rücken. Ihr Ziel ist es, komplexe Probleme in Teilaufgaben zu zerlegen. Durch diesen Fokus auf den Lösungsweg sollen sie lernen, Aufgaben systematisch zu lösen, statt lediglich Muster aus ähnlichen bekannten Aufgaben zu reproduzieren.
Durch Reasoning können Modelle außerdem ihre Rechenleistung gezielt skalieren, da sie die Anzahl ihrer iterativen Lösungsschritte je nach Aufgabenkomplexität dynamisch anpassen. Ein Vorbild für dieses Prinzip findet sich im Schach: AlphaZero – ein Modell, das durch Reinforcement Learning übermenschliche Spielstärke erreichte, ohne jemals menschliche Züge gesehen zu haben. Doch lässt sich dieser Selbstverbesserungs-Ansatz auf Probleme in natürlicher Sprache übertragen?
Genau hier setzen Modelle wie DeepSeek R1 und OpenAI o3 an – leistungsfähige Reasoning-Modelle mit dem Anspruch, autonom ihre Schlussfolgerungsfähigkeiten zu verbessern. Was können wir von AlphaZero lernen, um die Funktionsweise von Reasoning-Modellen besser zu verstehen?
DeepSeek R1: Ein Open-Source Reasoning-Modell
Während proprietäre Modelle wie Grok3 THINK, OpenAI’s o1 und o3 nur wenig über ihren Trainingsprozess preisgeben, gibt uns DeepSeek R1 durch ein veröffentlichtes Paper Einblicke in die Methodik und Architektur. Das macht es besonders spannend für die Forschungsgemeinschaft.
Was macht DeepSeek R1 besonders?
Reinforcement Learning: Klassische Sprachmodelle lernen durch überwachte Trainingsdaten (Supervised Learning). DeepSeek R1 hingegen optimiert seine Schlussfolgerungen durch selbstständige Exploration. Ähnlich wie AlphaZero im Schach testet DeepSeek R1 verschiedene Lösungswege, verwirft schlechte und verstärkt erfolgreiche Strategien.
Open-Source: Im Gegensatz zu proprietären Modellen stellt DeepSeek R1 nicht nur seine Architektur, sondern auch sein Research Paper und sogar ein eigens erstelltes Reasoning-Dataset der Wissenschafts-Community zur Verfügung. Zudem gibt es kleinere Destillationen des Modells, die den praktischen Einsatz erleichtern.
Technische Eckdaten:
- Mixture of Experts (MoE)-Modell mit 671B Parametern, von denen pro Anfrage nur 37B aktiv sind.
- Veröffentlichte Daten & Benchmarks: Das Modell zeigt in vielen Tests Leistungen auf Augenhöhe mit OpenAI’s o1 oder sogar darüber.
Reinforcement Learning
Ein tiefer Einblick in Reinforcement Learning würde zu weit führen, doch die Grundidee ist simpel: Ein Modell lernt durch Versuch und Irrtum, welche Strategien langfristig erfolgreich sind. Dabei erhält es für korrekte Entscheidungen positive Rückmeldungen (Rewards) und für falsche negative (Penalties).
Das Problem mit Sprachmodellen
Während im Schach klar definiert ist, wann eine Partie gewonnen oder verloren ist, fehlt eine solche eindeutige Bewertungsgrundlage in der Sprachverarbeitung. Es gibt keine universelle Metrik, die objektiv die „beste Zusammenfassung“, das „beste Gedicht“ oder den „besten Nachrichtenartikel“ bestimmen kann.
Daher fokussiert sich das Reinforcement Learning von Reasoning-Modellen auf validierbare Aufgaben wie Mathematik oder Programmierung. Hier können die Lösungen des Modells durch einen Gleichungslöser oder einen Compiler überprüft werden. Dieses direkte Feedback ist essenziell für den Lernprozess.
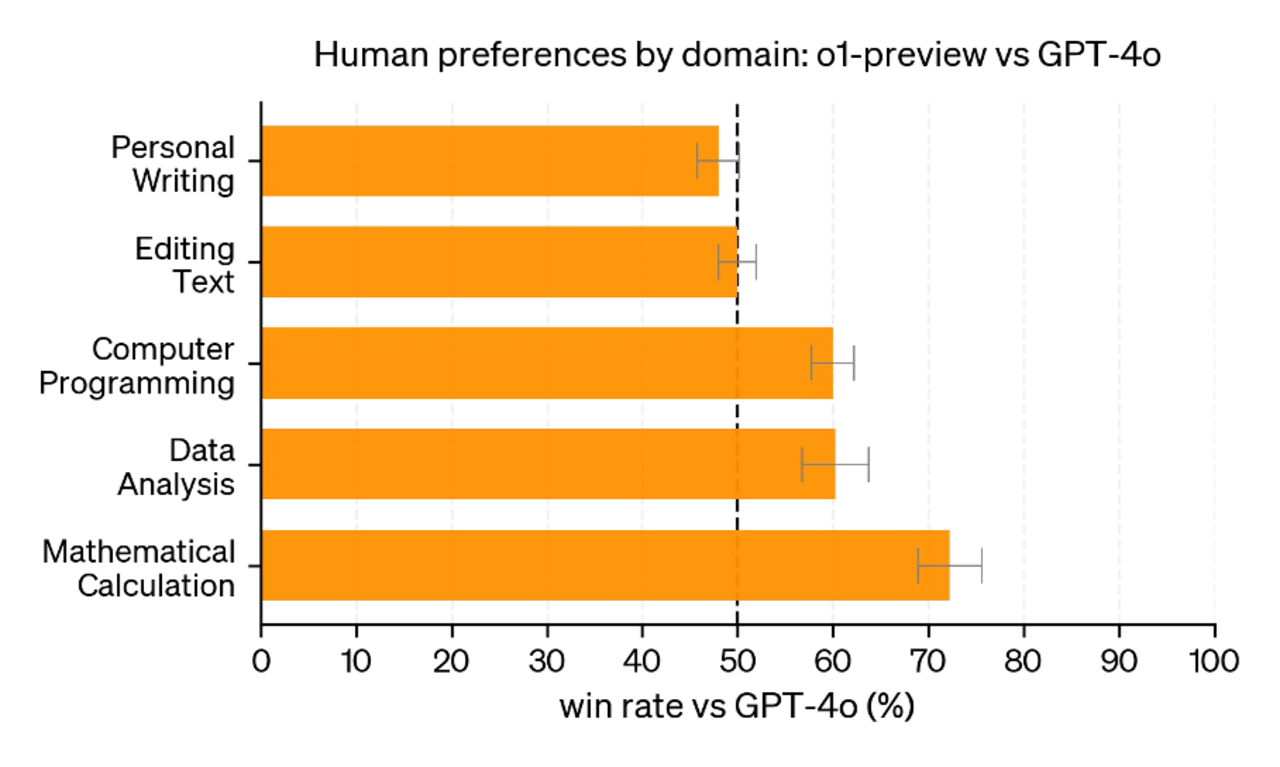
Bereits bei OpenAI’s o1 konnte beobachtet werden, dass sich die Fähigkeiten im Bereich Mathematik und Coding deutlich verbesserten. Eine vergleichbare Verbesserung für kreative Sprachaufgaben blieb jedoch aus.
Warum herkömmliches Training nicht ausreicht
Eine gängige Methode zur Feinabstimmung moderner Sprachmodelle ist Reinforcement Learning from Human Feedback (RLHF), entwickelt von OpenAI. Dabei werden Modelle nach ihrem Vortraining auf riesigen Datenmengen an menschliche Präferenzen angepasst. Während dieser Phase wird weniger das Wissen oder die Fähigkeiten eines Modells erweitert, sondern eher seine „Persönlichkeit“ geprägt: Soll es höflich oder sachlich sein? Wie viel Humor soll es verwenden? Welche Fragen soll es aus Sicherheitsgründen verweigern?
Allerdings gibt es wissenschaftliche Arbeiten, die argumentieren, dass für diesen Schritt kein aufwändiges Reinforcement Learning notwendig sei. Methoden wie Direct Preference Optimization (DPO) oder einfaches Feintuning werden mittlerweile oft als effizienter angesehen, da sie weniger Rechenressourcen benötigen und stabilere Ergebnisse liefern.
Doch bei mehrstufigem Schlussfolgern (Multi-Step Reasoning) könnten diese einfacheren Methoden an ihre Grenzen stoßen.
Ein Hauptproblem dabei ist das Credit-Assignment-Problem, das eng mit Reinforcement Learning verknüpft ist. Während Sprachmodelle für direkte Frage-Antwort-Paare leicht trainiert werden können, ist das Training für lange Schlussfolgerungsketten weitaus schwieriger:
- Welche Teile der Schlussfolgerung waren besonders hilfreich?
- Welche waren überflüssig?
Übliche Trainingsdaten geben nur Rückmeldung darüber, ob das Endergebnis richtig oder falsch ist. Da Sprachmodelle jedoch Wort für Wort generieren, bleibt unklar, welche Worte tatsächlich zur Lösung beigetragen haben und welche nur Füllmaterial waren. Dies ist ein zentrales Problem, für das Reinforcement Learning eine Lösung finden soll.
In klassischen RL-Methoden wird hierfür ein Critic-Modell trainiert. Dieses Modell ist meist genauso groß wie das Sprachmodell selbst und dient einzig dazu, den Wert einzelner Entscheidungen zu schätzen – ein Prozess, der extrem ressourcenintensiv ist.
Eine der größten Innovationen von DeepSeek R1 liegt in der Nutzung von Group Relative Policy Optimization (GRPO). Diese Methode erlaubt es, auf ein eigenständiges Critic-Modell zu verzichten, wodurch das Training effizienter und weniger rechenintensiv wird.
Parallelen zu AlphaZero
AlphaZero hilft uns, die Idee hinter Reasoning-Modellen besser zu verstehen. Dieses berühmte Schachsystem erlangte übermenschliches Niveau – vollkommen ohne menschliche Partien oder Expertenwissen. Der Schlüssel lag im Self-Play, einer Form des Reinforcement Learning, bei der das Modell kontinuierlich gegen sich selbst spielte, Fehler erkannte und neue Strategien entwickelte.
Reasoning-Modelle wie DeepSeek R1 oder Grok 3 THINK versuchen nun, die gewaltigen Erfolge von Sprachmodellen mit der Selbstverbesserungsfähigkeit von AlphaZero zu kombinieren. Der zentrale Gedanke dabei ist, dass ein Modell nicht nur aus vorgegebenen Beispielen lernt, sondern eigenständig neue Lösungsstrategien erkundet.
Hierbei gibt es zwei klare Parallelen zwischen AlphaZero und modernen Reasoning-Modellen:
1️⃣ Reinforcement Learning und Self-Improvement
AlphaZero bewies die Stärke von Reinforcement Learning in Bereichen mit großem Zustandsraum (State Space), etwa im Schach oder in der Robotik. Das Modell konnte durch kontinuierliche Erkundung des Spielfelds neue Strategien entwickeln – ungebunden an menschliche Vorgaben. Ein ähnlicher Ansatz wird nun auf Reasoning-Modelle übertragen:
- Exploration statt Auswendiglernen: Während klassische Sprachmodelle sich auf bekannte Muster stützen, sollen Reasoning-Modelle neue Lösungswege erforschen.
- Validierbare Domänen: Damit Reinforcement Learning effektiv funktioniert, braucht es ein überprüfbares Feedback. Im Schach ist das etwa eine Matt-Position, in der Robotik das Erreichen eines Zielpunkts. Aus diesem Grund konzentrieren sich Reasoning-Modelle besonders auf Mathematik- und Programmieraufgaben, bei denen man den Erfolg programmatisch validieren kann.
- Neuartige Strategien entwickeln: Ein Modell, das sich durch Reinforcement Learning verbessert, kann potenziell auf kreative Lösungen kommen, die in keinem Trainingsdatensatz existieren.
Diese Mechanismen ermöglichen es Reasoning-Modellen theoretisch, sich über ihre initialen Trainingsdaten hinaus weiterzuentwickeln – ein Schritt in Richtung echter künstlicher Problemlösungskompetenz.
2️⃣ Graphensuche zur Inferenzzeit
Neben dem Training gibt es eine weitere entscheidende Gemeinsamkeit zwischen AlphaZero und modernen Reasoning-Modellen – nämlich die Art der Problemlösung zur Inferenzzeit, also während der eigentlichen Nutzung des Modells.
AlphaZero generierte seine Spielzüge mithilfe eines neuronalen Netzwerks, doch das allein reichte nicht aus, um Weltklasse-Niveau zu erreichen. Das Modell selbst hatte ein Elo-Rating von etwa 2500, was einem internationalen Meister, aber nicht den stärksten menschlichen Spielern entsprach. Erst durch die Monte-Carlo-Baumsuche (MCTS), eine systematische Graphensuche, konnte AlphaZero seine Gegner dominieren.
Wie funktioniert das?
- Das neuronale Modell schlägt Spielzüge vor.
- Das System simuliert mögliche Gegenzüge und deren Auswirkungen.
- Es baut einen Graphen möglicher zukünftiger Spielverläufe auf und bewertet diese.
- Durch iterative Simulation verbessert es seine Entscheidungsfindung.
Dieser Mechanismus ist so leistungsstark, weil er das Modell flexibel skalierbar macht: Die Qualität der Entscheidungen steigt mit der Rechenzeit, die in die Simulation investiert wird.
Reasoning-Modelle verfolgen eine ähnliche Strategie – jedoch in natürlicher Sprache.
- Statt Schachzüge zu simulieren, generieren sie lange Schlussfolgerungsketten.
- Sie planen, evaluieren, revidieren und optimieren ihre Argumentationswege, wenn sie mit komplexen Problemen konfrontiert sind.
- Dieser Prozess ähnelt der Monte-Carlo-Baumsuche, findet aber nicht explizit über eine Graphensuche statt, sondern wird implizit durch neuronale Netzwerke erlernt.
Da Sprache eine weit größere Komplexität als Schach besitzt, ist der zugrundeliegende State Space noch viel gewaltiger. Ein Schachspiel hat eine klar begrenzte Anzahl an möglichen Zügen und Spielständen – doch die Variationen von Argumentationsketten in natürlicher Sprache sind nahezu unbegrenzt.

Hype vs. Realität
Reasoning-Modelle wie DeepSeek R1 haben zweifellos beeindruckende Fortschritte gezeigt – insbesondere in Bereichen wie Mathematik und Programmierung, in denen präzise und überprüfbare Lösungen existieren. Doch dieser Hype kann leicht in die Irre führen.
Die Fortschritte sind stark auf validierbare Domänen beschränkt.
Während sich mathematische Probleme oder Coding-Aufgaben durch klare Regeln und eindeutige Lösungen auszeichnen, fehlt ein solches strukturiertes Feedback in vielen anderen Anwendungsbereichen. Der Versuch, die Methoden auf offenere, weniger technische Domänen zu übertragen, bleibt bisher ohne durchschlagenden Erfolg. Es ist unklar, ob hier eine völlig neue Strategie notwendig wäre, um echte Fortschritte zu erzielen.
Von Hochleistung zu absurden Fehlern
Gerade in diesen schwierigeren Bereichen zeigen Sprachmodelle weiterhin all ihre bekannten Schwächen. Es sind dieselben Systeme, die in einem Moment komplexe mathematische Probleme lösen und im nächsten Moment an offensichtlichen logischen Fehlern oder trivialen Missverständnissen scheitern. Dieser Kontrast zwischen scheinbarer Brillanz und absurden Fehltritten macht die Grenzen aktueller Modelle besonders deutlich.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.