
Retrieval Augmented Generation Systeme stellen durch die Anbindung von externen Datenquellen zusätzliches Wissen für große Sprachmodelle (LLM) bereit. Dabei ruft das RAG-System relevante Dokumente aus der externen Datenquelle ab, woraus das Sprachmodell kontextbasierte Antworten liefert. Doch was beeinflusst die Relevanz? Wir stellen Ansätze aus aktueller Forschung zur Optimierung von RAG-Systemen vor.
Was ist Retrieval Augmented Generation (RAG)?
Große Sprachmodelle (LLMs) zeigen bemerkenswerte Fähigkeiten in der semantischen Verarbeitung und verfügen über umfangreiches (Welt-)Wissen. LLMs können allerdings veraltete Informationen liefern und in manchen Fällen faktische Ungenauigkeiten (Halluzinationen) produzieren.


Da LLMs nur periodisch auf einem großen Korpus öffentlicher Daten trainiert werden, fehlt ihnen aktuelles Wissen sowie private Daten, die für das Training nicht zugänglich sind.
Retrieval Augmented Generation (RAG) ist ein Ansatz in der Entwicklung von LLM-Anwendungen, um diese Einschränkungen zu überwinden.
Doch RAG-Systeme haben ihre eigenen komplexen Fallstricken. Self-Reflective Retrieval-Augmented Generation (SELF-RAG) ist ein neuer Ansatz, der die Qualität und Faktizität eines Sprachmodells durch Abruf und Selbstreflexion verbessert. Experimente zeigen, dass selbstreflektierende Systeme bei einer Reihe von Aufgaben die Ergebnisse deutlich übertreffen.
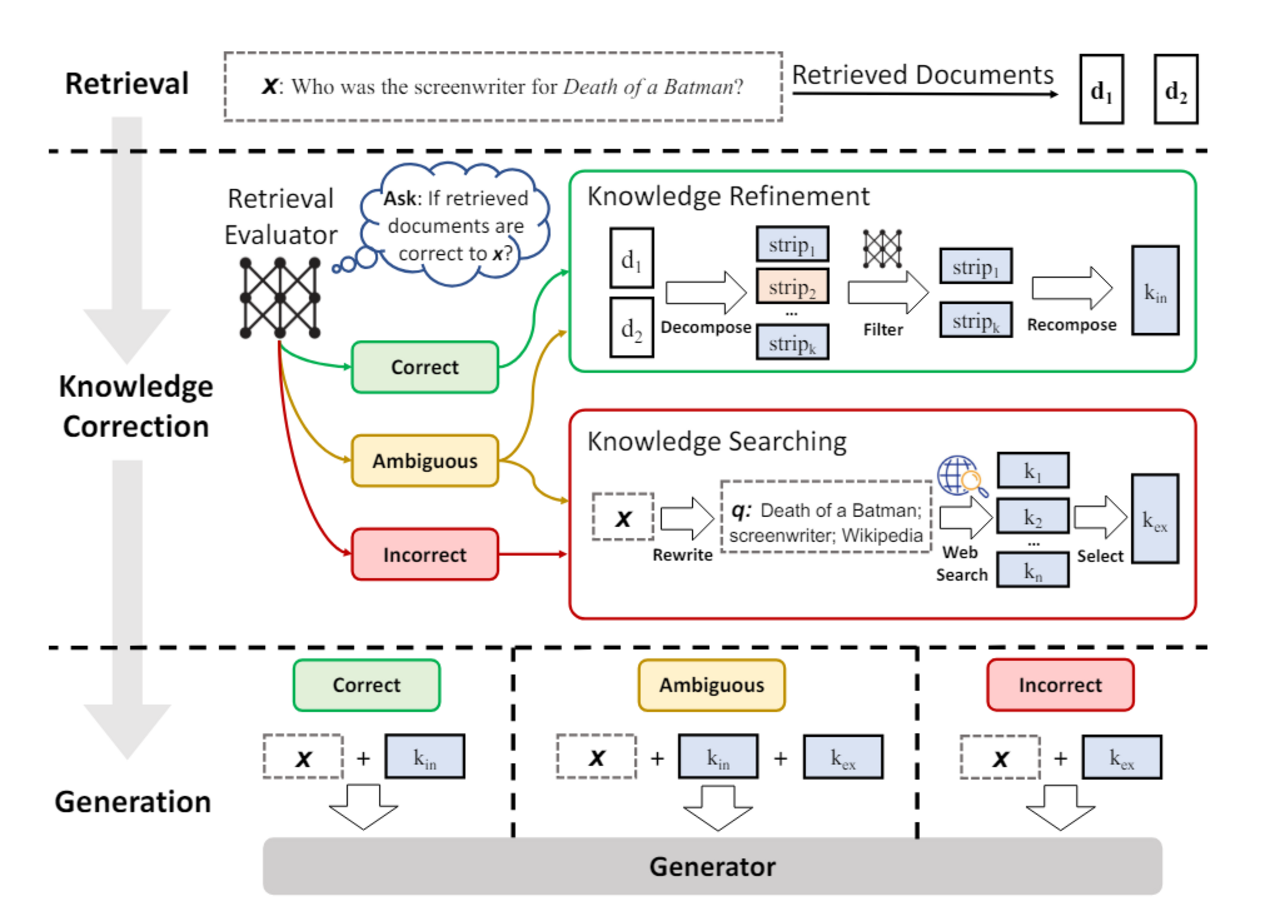
Relevanz der Dokumente
Die Relevanz der gefundenen Dokumente spielt eine entscheidende Rolle für die Leistung eines RAG-Systems. Irreführende Dokumente können zu schlechteren Ergebnissen und sogar zu noch mehr Halluzinationen führen. Zur Verbesserung der Qualität der Dokumentensuche gibt es zahlreiche Methoden zur Suchoptimierung, z.B. hybride Suche, Query Augmentation, Training der Vektor-Embeddings und semantische Verschlagwortung.
Eine neue Methode von SELF-RAG ist "Corrective RAG", welches in dem Paper "Corrective Retrieval Augmented Generation" vorgestellt wird. Der Kern dieser Methode besteht darin, dass die gefundenen Dokumente von einem LLM bewertet werden und anhand dieser Bewertung Folgeschritte abgeleitet werden, wie zum Beispiel eine zusätzliche Websuche.
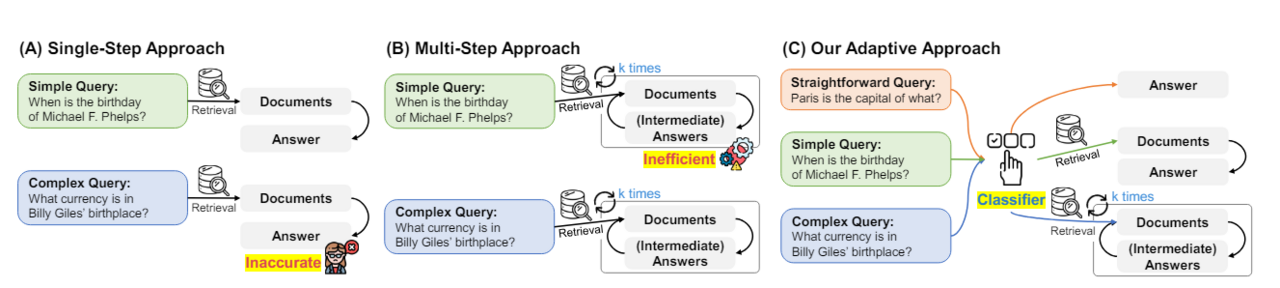
Komplexität der Anfrage
In der Forschungsarbeit "Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity" argumentieren die Autoren, dass Anfragen an ein LLM unterschiedlich komplex sind und daher unterschiedliche Lösungsstrategien benötigen.
Einige Fragen können direkt vom Modell beantwortet werden, andere benötigen ein RAG-System, da sie spezifisches Wissen verlangen. Besonders komplexe Fragen erfordern die Aggregierung von Informationen aus mehreren unterschiedlichen Quellen.
Um solche komplexen Anfragen zu bewältigen, benötigt ein RAG-System möglicherweise mehrere iterative Retrieval- und Analyseschritte. Ein System, welches jede einzelne Anfrage mit dieser komplexen Methodik bearbeitet, wäre allerdings langsam und teuer. Daher bietet sich ein erster Klassifikationsschritt an, der die Komplexität der Anfrage einschätzt und eine geeignete Lösungsstrategie auswählt.
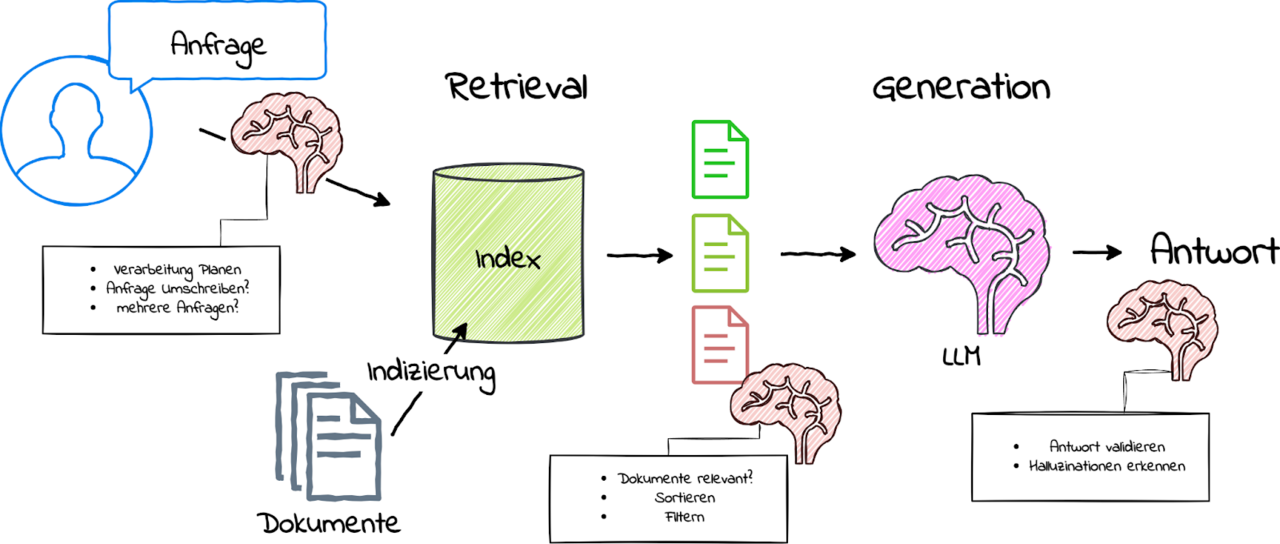
Wie in der Grafik visualisiert, kann ein selbstreflektives RAG-System mehrere zusätzliche Schritte umfassen. Ein Modul kann anhand einer Nutzeranfrage planen, welche Verarbeitungsschritte notwendig sind, oder ob die Anfrage für den Suchindex umgeschrieben werden muss. Ein weiteres Modul kann die gefundenen Kontextdokumente nach ihrer Relevanz sortieren und filtern. Noch ein weiteres Modul kann die Antworten validieren und Halluzinationen erkennen. Für diese zusätzlichen Schritte können kleinere LLMs oder speziell trainierte Sprachmodelle eingesetzt werden.
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Autor

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.