
Ein Fokus aktueller Forschung im Bereich der Large Language Models (LLMs) ist die Frage, wie man die enorm großen und rechenintensiven Modelle verkleinert, ohne dabei wesentliche Qualität einzubüßen. Für die praktische Anwendbarkeit von LLMs ist dies von entscheidender Bedeutung, zum Beispiel, um ein Sprachmodell auf einem mobilen Endgerät oder Edge-Device zu nutzen oder eine LLM-Anwendung kostengünstig auf lokaler Infrastruktur zu deployen, ohne dass dafür eine oder mehrere große Server-GPUs zu einem hohen Preis angeschafft werden müssen. Ein lokales Deployment ist vor allem für Anwendungen wünschenswert, die hohe Sicherheits- und Datenschutzstandards erfüllen müssen.
Für die Verkleinerung von LLMs, also die Konstruktion von SLMs (Small Language Models), gibt es verschiedene Ansätze:
- Training eines kleineren Modells „from Scratch“: Dies ist der offensichtlichste, aber auch aufwendigste Ansatz: Die Architektur des SLMs wird so konzipiert, dass es die gewünschte Anzahl an Parametern hat (z. B. nur 2 Milliarden statt mehr als 400 Milliarden) und dann auf einem großen Datensatz trainiert. Da der Datensatz für ein leistungsstarkes Endmodell wirklich sehr groß sein muss (Billionen von Wörtern umfassend), ist dieser Ansatz trotz der reduzierten Größe des Modells nur mit enormen Ressourcen (sprich: vielen großen GPUs und viel Speicher) umsetzbar.
- Quantisierung: Hierbei werden die Parameter und internen Repräsentationen des LLMs mit geringerer Präzision dargestellt. Normalerweise wird ein Parameter als Fließkommazahl mit 16 Bit Präzision dargestellt; durch Quantisierung kann diese Zahl jedoch auf bis zu 4 Bit reduziert werden. Das LLM benötigt dann nur noch ein Viertel des ursprünglichen Speicherplatzes auf der GPU. Verschiedene Quantisierungsmethoden existieren, die versuchen, den Quantization Loss, also den Leistungsabfall nach der Quantisierung, zu minimieren. Ein Vorteil der Quantisierung ist, dass sie unabhängig von und zusätzlich zu anderen Kompressionsmethoden verwendet werden kann.
- Pruning: Es ist schon lange bekannt, dass man einzelne Parameter oder ganze Teile aus fertig trainierten neuronalen Netzen entfernen (prunen) kann, ohne allzu viel Qualität einzubüßen. Das resultierende Netzwerk ist kleiner, aber weiterhin performant. Dafür müssen die „wichtigen“ und „unwichtigen“ Teile des Netzwerks auf irgendeine Weise identifiziert werden.
- Knowledge Distillation: Hier lernt ein kleineres „Student“-Modell das Verhalten eines größeren „Teacher“-Modells. Das Student-Modell muss zwar ebenfalls trainiert werden, aber mit einer deutlich geringeren Gesamtmenge an Daten.
Ein Team von Nvidia hat nun eine Methode vorgestellt, bei der Knowledge Distillation mit Pruning kombiniert wird, um kleine Modelle aus größeren zu erzeugen. Daraus ist die Modellfamilie Minitron entstanden.
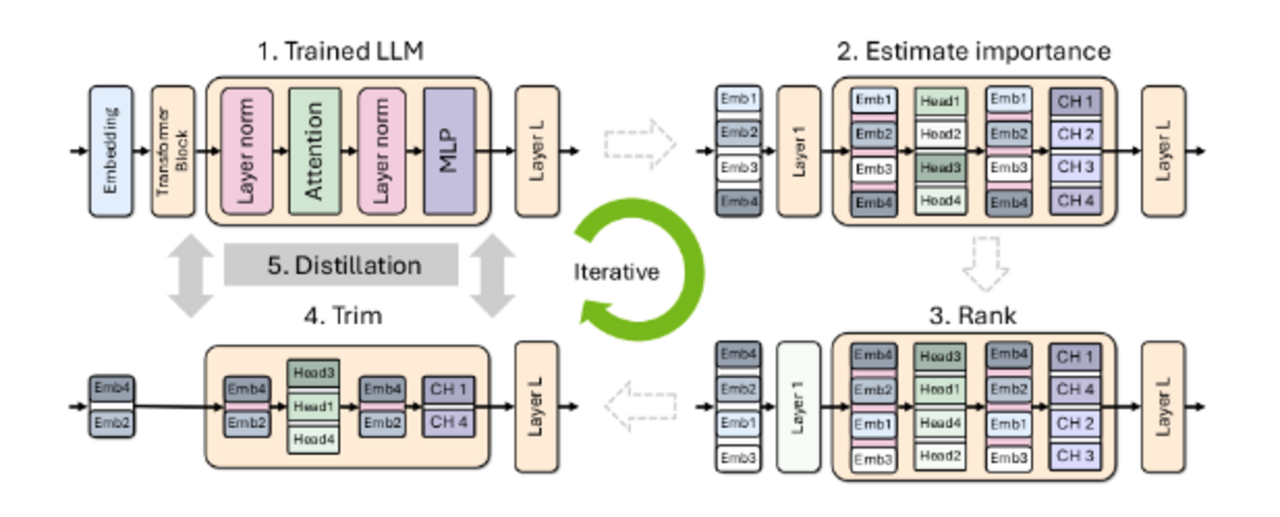
Wie funktioniert die Minitron-Methode?
Minitron basiert auf der Idee, ein großes, vortrainiertes LLM durch Pruning und Knowledge Distillation zu verkleinern. Der Prozess läuft iterativ ab und besteht aus folgenden Schritten:
- Wichtigkeitsanalyse: Zunächst wird die Wichtigkeit der einzelnen Komponenten des LLMs ermittelt, darunter Neuronen in den Feedforward-Schichten, Attention Heads und Embeddings des Modells. Die Wichtigkeit wird anhand der Größe der Aktivierungen (interner Zwischenergebnisse der Verarbeitung) auf einem kleinen Kalibrierungsdatensatz berechnet.
- Rank: Die Komponenten werden nach der berechneten Wichtigkeit sortiert.
- Trim: Die unwichtigsten Komponenten werden entfernt.
- Knowledge Distillation: Das reduzierte Modell (Student) wird nun mithilfe des ursprünglichen, großen Modells (Teacher) trainiert. Der Student lernt dabei, die Ausgaben und Zwischenzustände des Teachers zu imitieren.
Die Schritte 1-4 werden wiederholt, bis die gewünschte Größe des Modells erreicht ist.
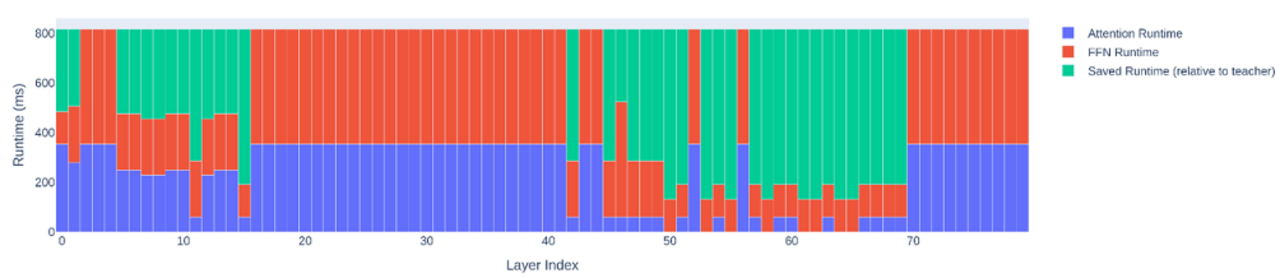
Welche Teile des Netzes können weg?
Wenn man visualisiert, wie viele Parameter pro Schicht am Ende geprunet wurden (hier für das größte Minitron-Modell mit 51 Milliarden Parametern), zeigt sich eine unregelmäßige Struktur:
Auf der X-Achse werden die Layer von vorne (direkt nach dem Input) bis hinten (direkt vor dem Output) durchnummeriert, auf der Y-Achse wird die Laufzeit pro Layer angegeben.
Zur Interpretation sollte man eine wichtige Theorie über die Funktion der verschiedenen Schichten neuronaler Netze kennen.
Exkurs: Feature-Hierarchien in neuronalen Netzen
Die Idee hierarchischer Features stammt aus der Bildverarbeitung: Frühere Schichten eines neuronalen Netzes lernen einfache, lokale Features zu erkennen, wie Kanten oder Flächen, während spätere Schichten auf diesen aufbauend zunehmend globalere und komplexere Repräsentationen entwickeln, wie hier im Beispiel typische Teile eines Gesichts und dann ganze Gesichtstypen. Daher ist die Tiefe des Netzwerks für seine Effizienz entscheidend: Mit jeder zusätzlichen Schicht kann das Netz komplexere Interaktionen zwischen den Eingangsvariablen repräsentieren, wodurch die sogenannte Expressivität des Modells steigt.
Bei textuellen Eingaben werden vermutlich analog in früheren Schichten einfachere Features wie die Wortreihenfolge analysiert, während spätere Schichten zunehmend komplexe Features wie Syntax, Morphologie und Semantik verarbeiten (vgl. Rogers, Kovaleva, Rumshisky, 2021). So würde eine komplexe Information über einen Textabschnitt, etwa dass er eine Drohung impliziert oder sich für Demokratie ausspricht, erst in einer späteren Schicht als Resultat der zuvor extrahierten Informationen repräsentiert. Die folgende Grafik verdeutlicht die Analogie zwischen Bild und Text, hier am Beispiel der hierarchischen Syntax eines Satzes.
Interpretation des Prunings
In unserem Beispiel erscheinen besonders wichtig und damit für das Pruning unantastbar sowohl die letzten Schichten zu sein, die die komplexesten Konzepte repräsentieren und unmittelbar vor dem Output des Modells, sprich der berechneten Wahrscheinlichkeitsverteilung für das nächste Wort, liegen, als auch ein Block in der frühen Mitte des Modells, in dem Konzepte „mittlerer” Komplexität repräsentiert sind. Der darauf folgende Block an Schichten kann dagegen massiv geprunet werden, hier scheint also viel unwesentliche oder redundante Information kodiert. Die frühen Schichten, die in direktem Kontakt mit dem analysierten Text stehen, können ebenfalls teils deutlich reduziert werden.
Nach der Theorie der Feature-Hierarchien hätte man dagegen eher eine U-Kurve erwartet: Den frühen Schichten käme hohe Wichtigkeit zu, da sie fundamentale Features kodieren, auf denen die komplexeren aufbauen, und den späten Schichten ebenfalls, da sie das Resultat der Analyse enthalten, die komplexen Features, die für die Ausgabe entscheidend sind. Die mittleren Schichten würden hingegen eher unwesentliche Bedeutungsnuancen oder redundante Zwischenresultate enthalten. Diese Intuition wird hier aber nur teilweise (in Hinblick auf den zweiten Teil des U’s) bestätigt. Das experimentelle Resultat erinnert daran, dass KI-Forschung stark empirisch geprägt ist und man theoriegeleiteten Intuitionen nicht ohne Weiteres vertrauen kann.
Vorteile von Minitron
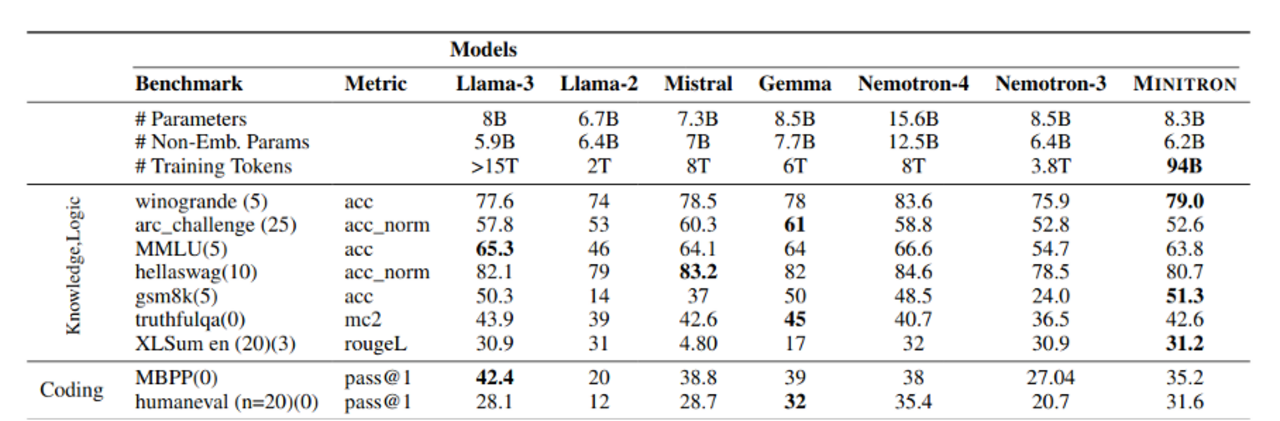
Der Hauptvorteil der Methode ist die gesteigerte Effizienz beim Training kleiner Modelle. Hat man einmal ein leistungsstarkes Modell aufwendig trainiert (bzw. anderweitig zur Verfügung), können kleinere Modelle mit einem Bruchteil des Aufwands mit der vorgeschlagenen Methode erzeugt werden. Die folgende Tabelle stellt die Anzahl benötigter Trainingstokens der Performance gegenüber. Minitron ist annähernd so performant wie vergleichbar große, voll trainierte Modelle, braucht aber deutlich weniger Tokens und damit weniger Zeit und Energie zum Trainieren.
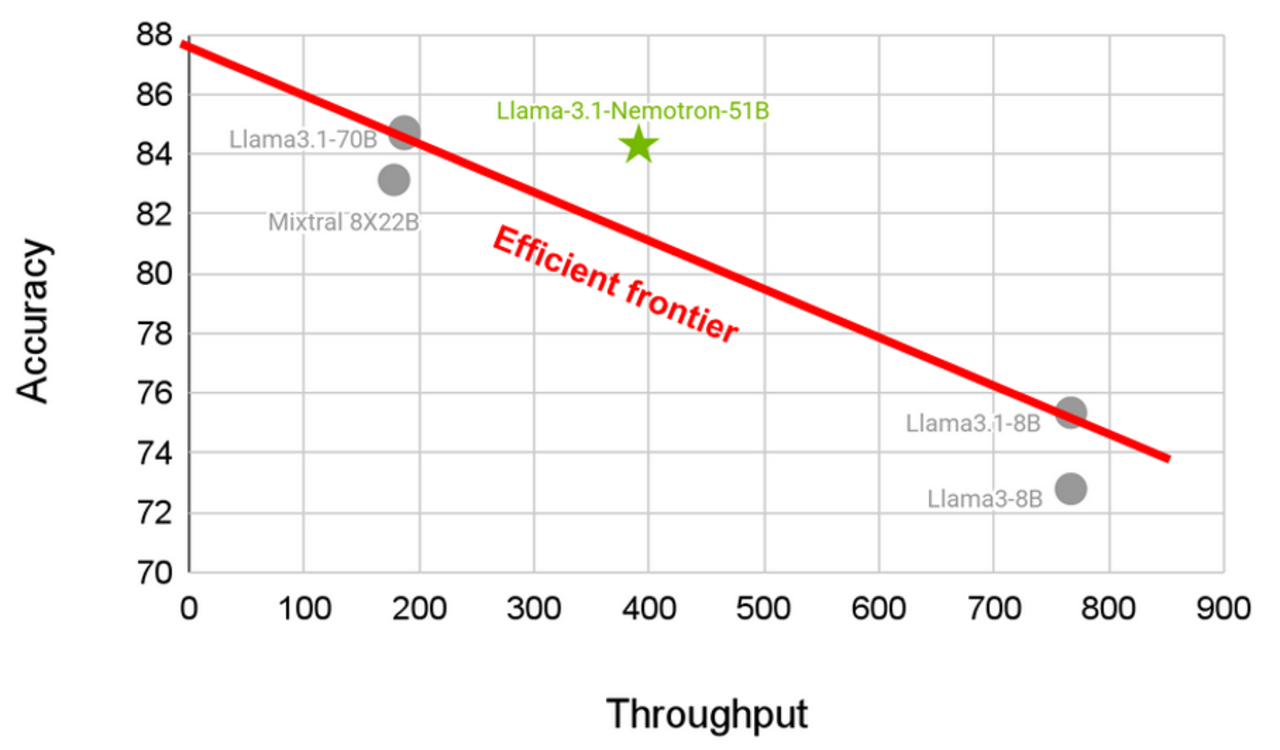
Das kleinere Modell benötigt weniger Rechenzeit und hat damit einen höheren Durchsatz (mehr verarbeitete Tokens pro Sekunde), erreicht aber fast die gleiche oder sogar höhere Performance als größere Modelle. Die aus bisherigen Modellen interpolierte lineare Obergrenze möglicher Performance bei gleichem Durchsatz wird damit durchbrochen.
Fazit
Minitron ist ein vielversprechender Ansatz zur Erzeugung kleinerer, effizienter LLMs. Die Kombination aus Pruning und Knowledge Distillation ermöglicht es, auch mit kleineren Datenmengen und geringerer Rechenpower starke Modelle zu erzeugen. Auch Akteure, die nicht die Ressourcen haben, ein Modell von Grund auf zu trainieren, können effiziente Modelle aus größeren Modellen erzeugen. Denkbar wäre, die Methode mit einem parameter-effizienten Finetuning eines großen Modells und anschließender Destillation dieses Modells in ein kleineres Modell zu kombinieren, um ein kleines, für einen spezifischen Use-Case optimiertes Modell zu erhalten. Die Abhängigkeit der KI-Technologie von riesigen kuratierten Datensätzen und großen Serverfarmen wird in jedem Fall reduziert und damit die Nutzung von KI ein Stück weit demokratisiert.
Zugang zu Minitron auf Huggingface
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Headergrafik Alexas_Fotos von pixabay
Datum: 12.11.2024
Autor

David Reuschenberg
David ist Experte für KI und Machine Learning mit Schwerpunkt auf Natural Language Processing (NLP) und Generative KI. Sein Studium der Informatik an der Freien Universität Berlin und der Technischen Universität Berlin schloss er 2023 mit einem Master mit Spezialisierung auf Kognitive Systeme ab. Seit März 2024 verstärkt David das Team von Ontolux und arbeitet dort an NLP-Fragestellungen, insbesondere unter Verwendung von Large Language Models. Hierzu zählen die Erkennung von Entitäten und Relationen sowie Generierung von Wissensgraphen aus unstrukturierten Texten, und die Entwicklung von Chatbot- und RAG-Systemen.