
Moderne KI-Modelle, wie beispielsweise GPT-4o, integrieren zunehmend multimodale Fähigkeiten. Das bedeutet, sie sind nicht mehr nur auf Text beschränkt, sondern verarbeiten auch Bilder, Videos und Audios. Diese Entwicklung eröffnet völlig neue Möglichkeiten für die Interaktion mit KI und eine Vielzahl innovativer Anwendungen.
Möglichkeiten multimodaler LLMs
Bildbeschreibung: Sie generieren präzise Beschreibungen von Bildern, was für sehbehinderte Menschen oder in der Bildanalyse nützlich ist.
Videoverstehen: Sie analysieren Videos und erkennen relevante Ereignisse, zum Beispiel in der Sicherheitsüberwachung, oder beim automatischen Generieren von Untertiteln.
Virtuelle Assistenten: Dank der Fähigkeit, multimodale Daten zu verarbeiten, werden virtuelle Assistenten noch interaktiver und vielseitiger.
Forschungserfolge und der Blick auf Open-Source-Modelle
Obwohl die genauen Verfahren proprietärer Modelle wie GPT-4o nicht öffentlich zugänglich sind, gibt es in der Forschung enorme Fortschritte. Ein Beispiel hierfür ist Llama Omni, ein auf dem Llama-3.1-8B-Instruct-Modell basierendes System, das speziell für die sprachbasierte Interaktion mit LLMs entwickelt wurde. Llama Omni ermöglicht es, direkt aus Spracheingaben Text und Sprachantworten zu generieren, ohne dass eine Transkription erforderlich ist. Darüber hinaus hat Meta mit Llama 3.2 Vision Modelle vorgestellt, die spezielle visuelle Komponenten integrieren, um Bilddaten zu verarbeiten. Diese Fortschritte zeigen das Potenzial von Open-Source-Modellen und ebnen den Weg für eine breitere Nutzung multimodaler LLMs.
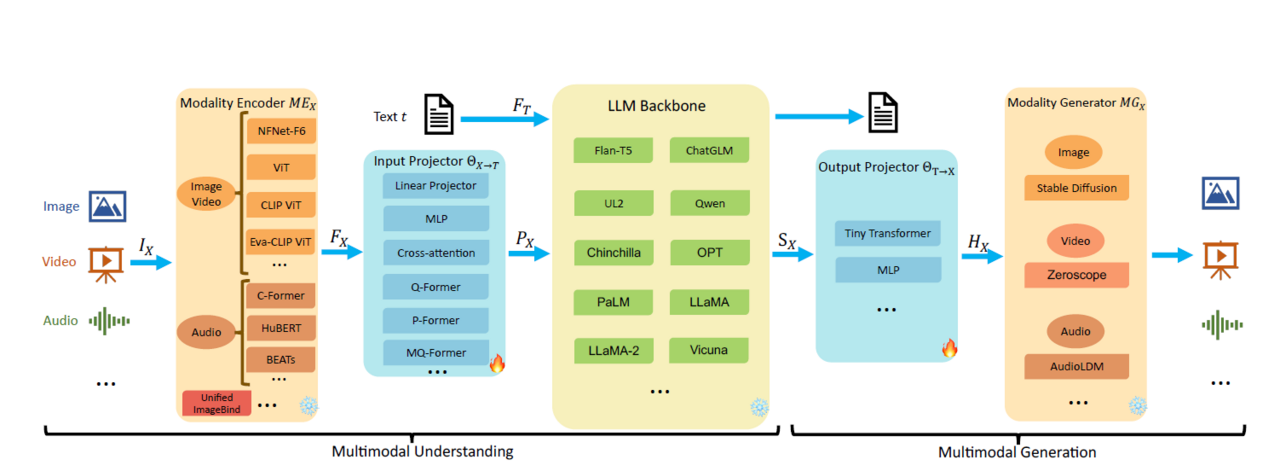
Wie funktionieren sie? Komponenten multimodaler LLMs
Multimodale LLMs bestehen in der Regel aus mehreren Komponenten, die zusammenarbeiten, um Modalitäten zu verarbeiten:
Modalitäts-Encoder: Diese Komponente ist für die Verarbeitung der Eingaben aus den verschiedenen Modalitäten zuständig. Ein Bild-Encoder würde beispielsweise ein Bild in ein Format umwandeln, das vom LLM verarbeitet werden kann. Für verschiedene Modalitäten werden unterschiedliche Encoder benötigt, beispielsweise NFNet-F6, ViT oder CLIP ViT für Bilder oder C-Former, HuBERT oder BEATs für Audiodaten.
Eingabe-Projektor: Der Eingabe-Projektor ist dafür zuständig, die von den Modalitäts-Encodern erzeugten Merkmale (Features) an den Textmerkmalraum anzugleichen, um eine reibungslose Verarbeitung durch das LLM zu gewährleisten.
LLM-Backbone: Dies ist die Kernkomponente des Multimodalen-LLM (MM-LLM). Sie nutzt die verarbeiteten Informationen aus den verschiedenen Modalitäten, um Aufgaben wie Textgenerierung, Fragenbeantwortung oder Inhaltserstellung durchzuführen. Bekannte LLMs sind beispielsweise Flan-T5, Qwen und LLaMA.
Ausgabe-Projektor: Die Ausgaben des LLM werden vom Ausgabe-Projektor in ein Format umgewandelt, das für die Generierung verschiedener Modalitäten geeignet ist.
Modalitäts-Generator: Diese Komponente verwendet die Ausgaben des Ausgabe-Projektors, um Inhalte in den verschiedenen Modalitäten zu generieren.
Multimodale Systeme: Zusammengesetzt, aber nicht End-to-End trainiert
Ein entscheidender Punkt bei vielen multimodalen Modellen ist, dass sie nicht End-to-End trainiert werden. Stattdessen werden die Modalitäten wie Bilder oder Audio separat vortrainiert, und ihre Repräsentationen werden erst später im multimodalen Modell zusammengeführt. Während des Trainings bleiben diese vortrainierten Module oft „eingefroren“, d.h. ihre Parameter werden nicht verändert. Stattdessen lernen sogenannte Projektoren, die Repräsentationen der verschiedenen Module ineinander zu überführen und so eine Verbindung zwischen den Modalitäten herzustellen.
LLaMA-Omni setzt z.B. auf einen vortrainierten Speech-Encoder (Whisper) für die Verarbeitung von Spracheingaben.
Herausforderungen des multimodalen Trainings:
Einer der Hauptgründe für das Einfrieren der Module ist die Größe und Komplexität multimodaler Modelle. Das Training eines so großen Modells von Grund auf wäre extrem rechenintensiv und würde enorme Datenmengen erfordern.
Hochwertige Trainingsdaten, die verschiedene Modalitäten miteinander in Beziehung setzen, sind viel seltener als beispielsweise Textdaten.
Vorteile des Einfrierens:
Durch das Einfrieren der vortrainierten Module können die bereits gelernten Repräsentationen der einzelnen Modalitäten bewahrt werden. Die Projektoren müssen dann lediglich lernen, diese Repräsentationen aufeinander abzustimmen, was die Trainingszeit und den Datenbedarf reduziert.
Zudem ermöglicht diese Strategie die Nutzung von hochwertigen vortrainierten Modellen wie CLIP für Bilder oder Whisper für Sprache. Diese Modelle wurden bereits auf riesigen Datensätzen trainiert und verfügen über ein breites Wissen in ihrer jeweiligen Modalität.
Die eingeschränkte Interaktion der Modalitäten
Multimodale Systeme haben trotz ihrer Leistungsfähigkeit auch Schwächen. Sie erinnern dabei an das Bild der „Drei Affen“. Jedes Modul – ob für Text, Bild oder Audio – nimmt nur einen Sinneskanal wahr. Anstatt die Welt in ihrer Gesamtheit zu erfahren und die komplexen Beziehungen zwischen verschiedenen Modalitäten zu lernen – wie es Menschen tun – sind diese Systeme darauf beschränkt, "miteinander zu sprechen". Das bedeutet, sie lernen, Repräsentationen einer Modalität in eine andere zu übersetzen, ohne jedoch ein tiefes Verständnis der zugrundeliegenden Zusammenhänge zu entwickeln.
Dennoch ist es beachtlich, dass diese Übersetzung von Repräsentationen überhaupt so gut funktioniert. Dieser Erfolg bestärkt die Annahme, dass LLMs nicht bloß Daten auswendig lernen, sondern tatsächlich in der Lage sind, sinnvolle Repräsentationen der Welt zu erlernen.
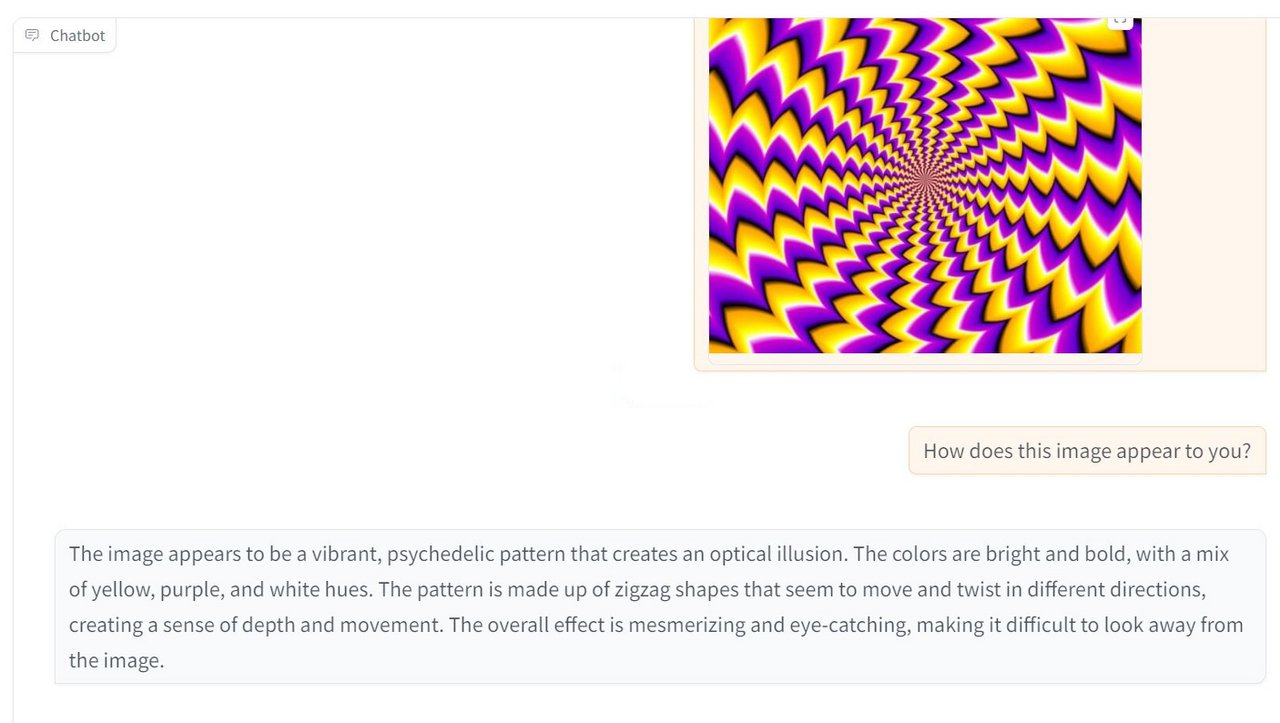
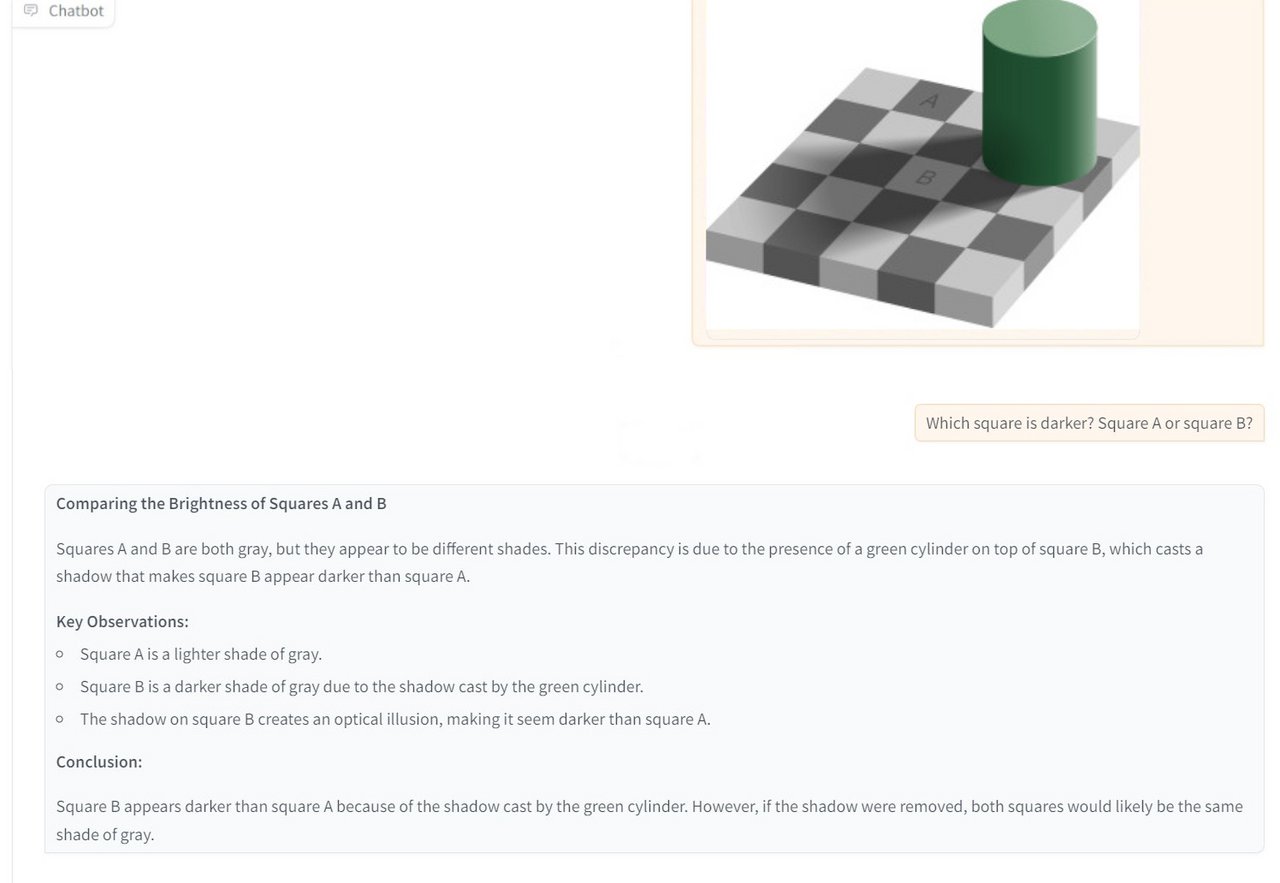
Open-Source-Vorreiter
Offene Modelle wie LLaMA 3.2 Vision zeigen das Potenzial multimodaler KI-Entwicklung in der Open-Source-Community. Sie ermöglichen es Entwicklern, leistungsfähige multimodale Anwendungen zu erstellen und für spezielle Anwendungsfälle zu optimieren. Von Bildbeschreibungen bis hin zu interaktiven virtuellen Assistenten.
Beispielergebnisse LLama 3.2 Vision:
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Headergrafik KI-generiert via Dall-E 3
Datum: 07.10.2024
Autor

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.