Kaum war die neue Bildgenerierungsfunktion in GPT-4o freigeschaltet, wurden die sozialen Netzwerke mit Memes, Bildern und Grafiken überflutet. Doch wie macht das Modell das eigentlich?

Hype und Möglichkeit
Die neue Bildgenerierungsfunktion in GPT-4o wurde veröffentlicht und führte zu einer signifikanten Zunahme von Porträts im Simpsons-Stil, Muppet-Adaptionen oder Ghibli-Versionen auf LinkedIn, Instagram und anderen Plattformen. Die Popularität der neuen Funktion war so signifikant, dass OpenAI gezwungen war, die Serverkapazitäten zu erhöhen, um die überlasteten Server zu entlasten.
Es wurde schnell klar: GPT-4o kann weit mehr als nur Memes. Nutzer erzeugen damit inzwischen auch komplexe Infografiken, Logos oder realitätsnahe Illustrationen – und das durch einfache Prompts direkt im Chatfenster. Die Faszination war sofort da – und mit ihr auch die Frage: Wie macht das Modell das eigentlich?
Technischer Überblick
OpenAI hält sich wie gewohnt mit Details zurück. Es gibt keine vollständige Architekturübersicht oder konkreten Angaben zur Trainingsmenge, Auflösung oder Tokenisierung des neuen Bildgenerators. Stattdessen müssen wir uns mit wenigen Informationen aus offiziellen Systemkarten und Ankündigungen sowie mit technischem Vorwissen zu bisherigen Ansätzen behelfen.
Trotzdem lässt sich mit diesen Mitteln ein recht klares Bild zeichnen. Denn viele Ideen hinter GPT-4os Bildfunktion bauen auf den Erfahrungen früherer Bildgenerierungsmodelle auf – vor allem:
- DALL·E – OpenAIs eigenes, auf Diffusion basierendes Modell mit text-bild-verknüpfender CLIP-Architektur.
- DeepSeek Janus-Pro – ein im Januar 2025 veröffentlichtes Modell, das erstmals versucht, Bildgenerierung direkt im Transformer-Sprachmodell zu verankern.
Was bisher geschah: Die DALL·E-Pipeline
Auch vor GPT-4o konnte man über ChatGPT Bilder erzeugen – doch diese Bilder stammten nicht vom gleichen Modell, das auch unsere Texteingaben verstand und beantwortete. Stattdessen lief im Hintergrund eine mehrstufige Pipeline ab. Zunächst prüfte das Sprachmodell, ob der Prompt den Nutzungsrichtlinien entspricht, und maßregelte uns gegebenenfalls. Anschließend „übersetzte“ das Sprachmodell unsere Eingabe in eine visuell aussagekräftige Beschreibung. Dabei wurden wichtige Details explizit gemacht oder ausgeschmückt, weil die nachgeschalteten Bildmodelle damit bessere Ergebnisse liefern. Der überarbeitete Text wurde schließlich an ein externes Bildmodell wie DALL·E 2 oder DALL·E 3 weitergereicht.
Wie funktionierte DALL·E?
DALL·E basierte – wie die meisten modernen Bildgeneratoren – auf einem Diffusionsmodell. Dabei beginnt die Bildgenerierung mit einem zufälligen Rauschbild, das in mehreren Schritten „entrauscht“ wird, bis am Ende ein stimmiges Bild entsteht.
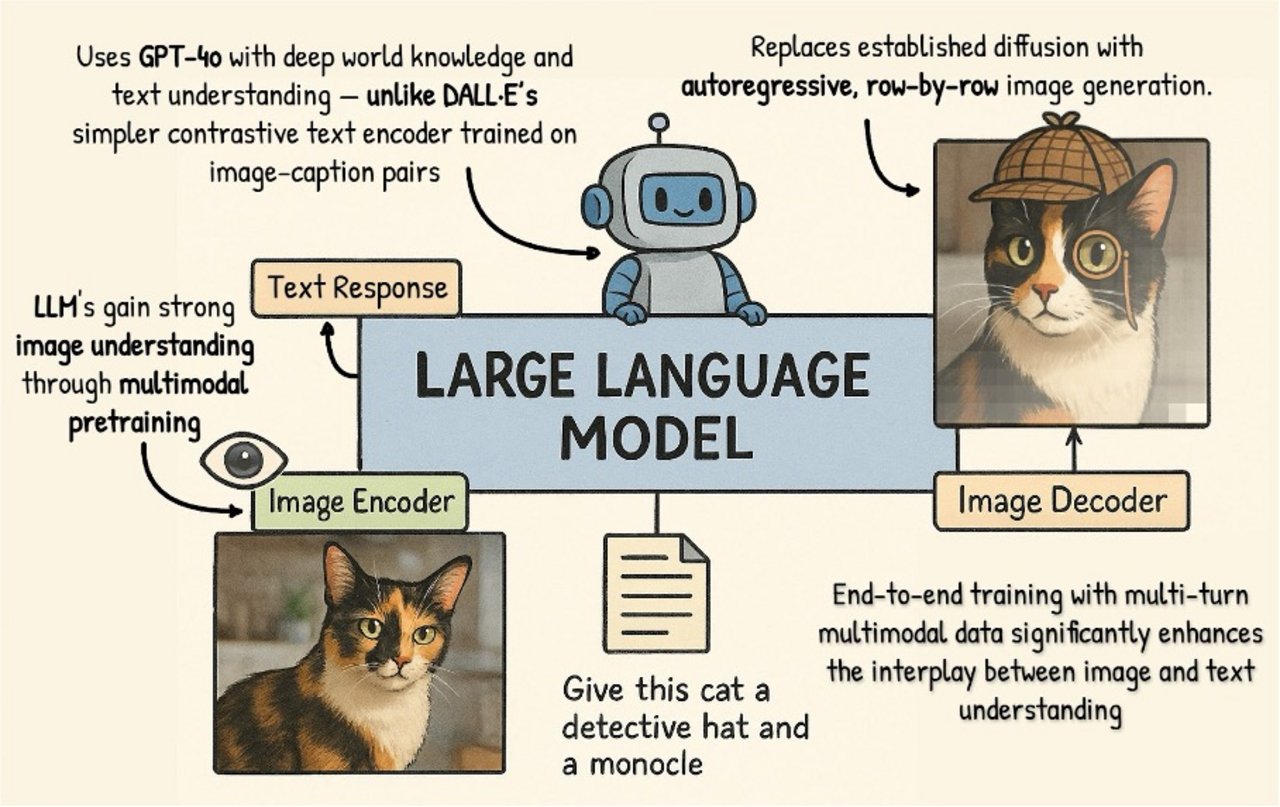
Die Steuerung dieses Prozesses erfolgt über eine spezielle Sprach-Bild-Schnittstelle namens CLIP. CLIP wurde kontrastiv trainiert, also darauf, Text-Bild-Paare miteinander abzugleichen: Es lernt, welche Bildbeschreibung zu welchem Bild passt – ohne dabei aktiv zu generieren. Im Bildgenerierungsprozess wird der eingegebene Prompt zunächst durch CLIP in einen semantischen Vektor übersetzt.
Dieser dient dann dem Diffusionsmodell – intern bei DALL·E ist das Modell GLIDE – als Orientierung: GLIDE beginnt mit Rauschen und versucht, daraus ein Bild zu erschaffen, das möglichst gut zur vom CLIP-Modell gegebenen Einbettung passt.
GLIDE erlernt seine Bildgenerierungsfähigkeiten größtenteils durch unstrukturierte, ungelabelte Bilddaten aus dem Internet und die Steuerbarkeit durch CLIP ist begrenzt.
Die Schwächen dieser Pipeline
Obwohl DALL·E (und insbesondere DALL·E 2 und 3) beeindruckende Bilder liefern konnten, war das System modular aufgebaut – Sprache und Bildverständnis waren klar voneinander getrennt. Dadurch entstanden mehrere Schwachstellen:
- Begrenztes Sprachverständnis: CLIP wurde mit Bild-Caption-Paaren trainiert und verfügt daher nur über eingeschränktes Sprachverständnis – weit entfernt von dem semantischen Tiefgang moderner Sprachmodelle.
- Fehlende Präzision bei Text im Bild: Textelemente wie Schilder oder Menüs wurden oft falsch oder unleserlich dargestellt. Das liegt zum einen daran, dass CLIP typischerweise auf einem CNN basiert, das nicht für Texterkennung optimiert ist, und zum anderen daran, dass in den Bild-Caption-Paaren meist nicht der vollständige Bildtext enthalten ist.
- Mangel an Dialog- und Kontextverständnis: Da Sprachverarbeitung und Bildgenerierung entkoppelt waren, konnten Bilder nicht sinnvoll über mehrere Interaktionen hinweg angepasst werden. Wer eine Figur „älter“ machen oder ein neues Objekt hinzufügen wollte, musste von vorn anfangen.
Limitierte Steuerbarkeit durch CLIP: Weil CLIP nur über bereits vorhandene, häufige Text-Bild-Paare gelernt hat, versagt DALL·E bei Konzepten, die selten oder ungewöhnlich sind. Fragt man DALL·E etwa nach einem Brief, der von einer linken Hand geschrieben wird, generiert es fast immer eine rechte Hand – schlicht weil solche Darstellungen häufiger in den Trainingsdaten vorkamen.
Janus-Pro von DeepSeek: Sprache und Bild integrieren
Anfang 2025 veröffentlichte das chinesische KI-Labor DeepSeek das Modell Janus-Pro, das einen ähnlichen Gedanken verfolgte: Sprache und Bildgenerierung nicht länger getrennt zu behandeln, sondern in einem einheitlichen großen Sprachmodell zusammenzuführen.
Der Ansatz bringt klare Vorteile: Das Sprachmodell kann seine Weltkenntnis und sein Kontextverständnis direkt in den Bildgenerierungsprozess einbringen.
Janus setzt weiterhin auf die Diffusions-Architektur – also jener Bildgenerierungslogik, die schrittweise aus einem Rauschbild ein realistisches Bild synthetisiert. Um die Effizienz und Qualität zu steigern, setzt Janus auf eine Weiterentwicklung dieses Ansatzes: den sogenannten Rectified Flow, ein alternativer Trainingsmechanismus für Diffusionsmodelle, der stabiler konvergiert und schneller hochwertige Ergebnisse liefern soll.
Ein zentrales Problem: Diffusion und autoregressive Sprachverarbeitung folgen völlig unterschiedlichen Prinzipien. Während Transformer-Modelle wie GPT Wörter oder Tokens eins nach dem anderen vorhersagen, funktioniert Diffusion über eine iterative Schleife, die dasselbe Bild immer wieder überarbeitet. Diese konzeptionelle Kluft macht es schwierig, die Bildgenerierung wirklich nahtlos in das Sprachmodell zu integrieren.
Janus löst das durch eine zweigleisige Architektur mit zwei verschiedenen Bildencodern:
- Der „Understanding“-Bildencoder ist verantwortlich für das Verstehen von Bildern in multimodalen Kontexten – z. B. wenn das Modell ein Bild als Input analysieren oder beschreiben soll.
- Der „Generation“-Bildencoder hingegen kümmert sich um die Bildsynthese – er verarbeitet die Zwischenschritte des Diffusionsprozesses (also die verschiedenen Rauschstufen) und kommuniziert diese mit dem Sprachmodell.
Diese Architektur ist ein pragmatischer Kompromiss: Sie verringert die Trennung zwischen Verstehen und Erzeugen, ohne sie ganz zu schließen.
GPT-4o: Ein neues Paradigma der Bildgenerierung
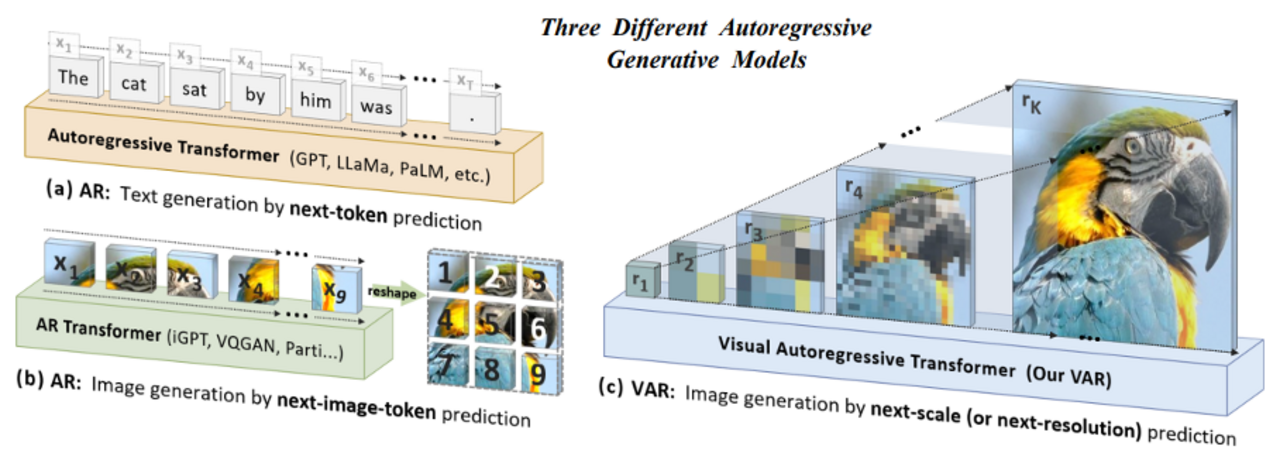
Das neue Bildgenerierungsmodell von GPT-4o führt weiter, was Janus-Pro begonnen hat: Doch statt auf ein separates Diffusionsmodell zu setzen, nutzt GPT-4o ein autoregressives Verfahren, das Bilder Zeile für Zeile, Pixel für Pixel oder in visuellen Patches erzeugt. Dadurch entfällt der Bedarf an einem separaten Bilddecoder – und die Generierung passt sich deutlich harmonischer an die Architektur eines Sprachmodells an.
Was ist an diesem Ansatz besonders?
Zunächst einmal ist das Vorgehen ungewöhnlich: Bilder sind zweidimensionale Daten, autoregressive Transformer-Modelle wie GPT wurden ursprünglich für linearen Text entwickelt. Ein Bild sequenziell zu erzeugen – so als würde man es in einer Art Fließtext schreiben – scheint auf den ersten Blick nicht besonders effizient oder intuitiv.
Doch der Vorteil liegt in der Architekturkompatibilität: Die autoregressive Bildgenerierung passt sich nahtlos in das bereits etablierte Token-basierte Denken der GPT-Modelle ein. Das Modell muss nicht lernen, zwei grundsätzlich verschiedene Repräsentationen (Text und Bild) zu synchronisieren – es nutzt denselben Mechanismus für beides.
Dieser Ansatz wurde in der Forschung bereits früher erprobt, etwa in OpenAIs eigenen Arbeiten zur Bildcodierung mit Googles Parti-Modell2022oder ByteDances VAR 2024. Die Herausforderung: Autoregressive Bildmodelle galten lange als zu langsam oder zu qualitativ schwach, um mit Diffusionsmodellen mitzuhalten. Doch GPT-4o scheint hier einen Durchbruch geschafft zu haben – mit beeindruckender Bildqualität, stilistischer Vielfalt und semantischer Präzision. Wahrscheinlich basiert dieser Fortschritt auf Ansätzen aus dem Visual Autoregressive Modeling (VAR). Anders als klassische autoregressive Modelle generiert VAR Bilder nicht strikt Token für Token, sondern nutzt eine hierarchische Struktur: Es beginnt mit einer groben Darstellung und verfeinert sie schrittweise. Dieser mehrskalige Aufbau orientiert sich an menschlicher Wahrnehmung und macht die Generierung effizienter.
Warum funktioniert es so gut?
Ein wesentlicher Faktor für die Bildqualität von GPT-4o ist das Weltwissen des zugrunde liegenden Sprachmodells – und wie dieses Wissen durch multimodales Training erweitert wurde. Schon frühere Versionen von GPT-4 waren in der Lage, Bilder zu interpretieren, allerdings war die Bildverarbeitung dort einseitig – Bilder dienten nur als Input, nicht als Teil der Ausgabe. Mit der neuen Version wurde auch die Bildgenerierung als Ziel in den Trainingsprozess integriert. Es wurde mit Bild-Text-Paaren trainiert, bei denen nicht nur das Bild verstanden, sondern auch synthetisiert werden sollte.
Dieser ganzheitliche Trainingsansatz – vom Prompt bis zur visuellen Ausgabe – ermöglicht es GPT-4o, Bilder nicht mehr auf Basis häufig gesehener Trainingsdaten zu erstellen, sondern mit dem Welt- und Sprachverständnis des zugrunde liegenden Sprachmodells. Dadurch ist die Bildgenerierung konzeptioneller, präziser und deutlich besser steuerbar als bei früheren Modellen.
Zudem hat OpenAI vermutlich – wie bei früheren Modellen – intensiv in das sogenannte Posttraining investiert: Es ist davon auszugehen, dass das Modell speziell für den Bildkontext mit hochwertigen, domänenspezifischen Daten feinabgestimmt wurde. OpenAI ist bekannt dafür, gezielt Domänenexpert:innen einzusetzen, um Trainingsdaten zu kuratieren, etwa für medizinische Inhalte, UI-Designs oder Bildungsgrafiken. All das fließt in die visuelle Ausdrucksstärke von GPT-4o ein.
Ein weiterer Vorteil: Dialogfähigkeit. Weil Text und Bild innerhalb desselben Modells verarbeitet werden, kann GPT-4o nicht nur auf einfache Prompts reagieren, sondern in mehrstufigen Gesprächen visuelle Inhalte schrittweise anpassen. Man kann sagen: „Mach das Licht wärmer“, „Füge noch eine Figur im Hintergrund hinzu“ oder „Ändere den Stil zu Aquarell“, und das Modell versteht diese Anweisungen – weil es den Kontext behalten und Bilder als Teil eines Gesprächsrahmens begreifen kann.
Die Schwächen sind andere
Natürlich ist auch dieser neue Ansatz nicht ohne Kompromisse. Die autoregessive Generierung ist rechenintensiv – denn jedes Bild muss sequenziell erzeugt werden. Das dauert länger als bei modernen Versionen von Diffusionsmodellen. Auch die Auflösung ist limitiert: GPT-4o scheint aktuell auf moderate Bildgrößen beschränkt zu sein (vermutlich etwa 1024×1024 px), da die sequentielle Vorhersage bei sehr großen Bildformaten schnell an ihre Grenzen stößt.
Auch visuelle Details, die nicht lateinische Schrift betreffen (z. B. arabisch, chinesisch, kyrillisch), wirken noch fehleranfällig – was darauf hindeutet, dass ein großer Teil des Trainingsmaterials auf westlich geprägte Inhalte ausgelegt war.
Die neue Version von GPT-4o markiert einen beeindruckenden Fortschritt für die Bildgenerierung mit KI. Vieles spricht dafür, dass die Fähigkeit zur Bildsynthese erst im Rahmen des Feintunings in das Modell integriert wurde. Umso spannender ist die Vorstellung, was möglich wäre, wenn diese Form der Multimodalität bereits im Pretraining - also von Beginn an - verankert wäre.
Ein solches Modell hätte nicht nur Zugriff auf sprachliche Strukturen und Zusammenhänge, sondern würde früh lernen, wie Sprache und visuelle Welt aufeinander verweisen – ein potenzieller Schlüssel zu einem tiefergehenden Verständnis physikalischer Realität durch KI.
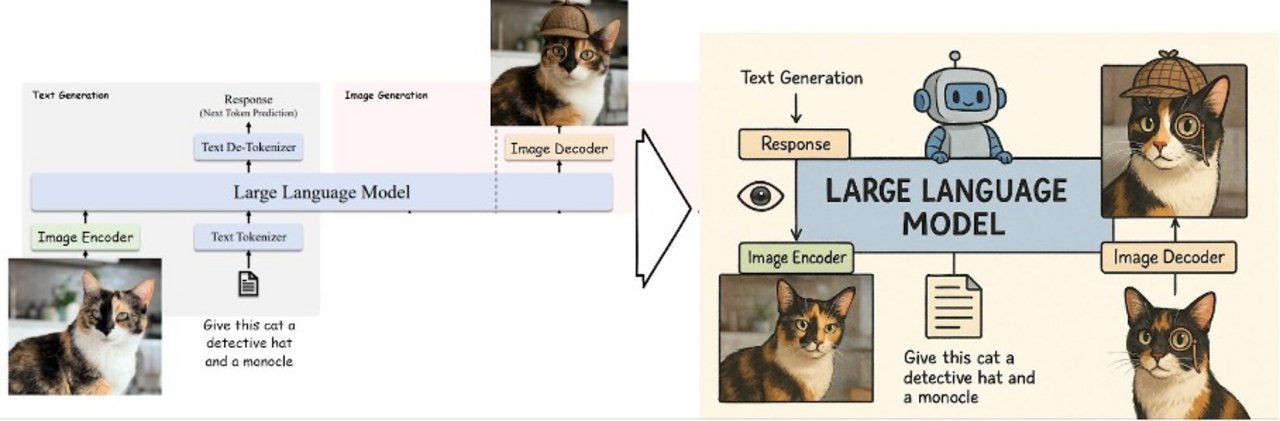
Headergrafik erstellt mit GPT-4o. Links der Skizzenprompt an ChatGPT, rechts das generierte Bild mit leichten Nachbearbeitungen. Trotz einiger Unsauberkeiten – etwa doppelter Katzen oder seltsam platzierter Pfeile – ist es erstaunlich, wie gut das Modell bereits komplexe Infografiken erzeugen kann. Noch vor Kurzem war so etwas für KI-Modelle praktisch unmöglich.
Datum: 02.04.2025
In unserer monatlichen Serie “KI-Journal Club” stellen wir wissenschaftliche Beiträge und Presseberichte vor aus den Bereichen Text Mining, Machine Learning, Generative Künstlicher Intelligenz & Natural Language Processing.
Wir beraten Sie gerne.
Sprechen Sie uns an

Bertram Sändig
Bertram ist Experte für KI- und Machine-Learning-Systeme mit einem Fokus auf NLP und Neural Search. Er hält einen B.Sc. in Informatik der FH Brandenburg und seit 2018 einen M.Sc. der TU Berlin mti den Schwerpunkten Machine Learning und Robotik. Parallel zum Studium war er fünf Jahre Leitender Software-Ingenieur im Space Rover Project des Luft- und Raumfahrtsinstituts der TU-Berlin. 2018 stieg er als Machine Learning Engineer bei Neofonie ein und leitet heute das Machine Learning Team bei ontolux, einer Marke der Neofonie GmbH. Mit großer Leidenschaft überführt er aktuelle Forschungsergebnisse in nutzbare Anwendungen für Kunden, vor allem an der Anpassung, Optimierung und Integration von Large Language Modellen in Suchsysteme und das Textanalyse-Toolkit von ontolux.